云聪OCR客户端使用教程
功能说明
云聪OCR客户端无需会员登录即可免费使用,基本可满足古籍业余爱好者使用频率,但是每天有一定次数限制。
云聪OCR客户端基于Umi-OCR 文字识别工具 制作而成,支持win7 x64 及以上的系统,所有客户端代码开源,解压即用。
1、可识别繁体+异体汉字4.8万,支持印刷字体、手写字体,识别率远高于开源繁体识别项目。
2、支持截图OCR、批量图片OCR、批量PDF古籍识别
3、支持识别结果导出格式:txt, jsonl, md, csv(Excel)。
下载
以下发布链接均长期维护,提供最新软件版本。
链接:https://pan.baidu.com/s/11jk4ngemH5K8Kki9B95CvA?pwd=6666 提取码:6666
软件发布包下载为 .7z 压缩包。自解压包可在没有安装压缩软件的电脑上,解压文件。
本软件无需安装。解压后,点击 Umi-OCR.exe 即可启动程序。
全局设置
Umi-OCR 支持的界面多国语言。在第一次打开软件时,将会按照你的电脑的系统设置,自动切换语言。
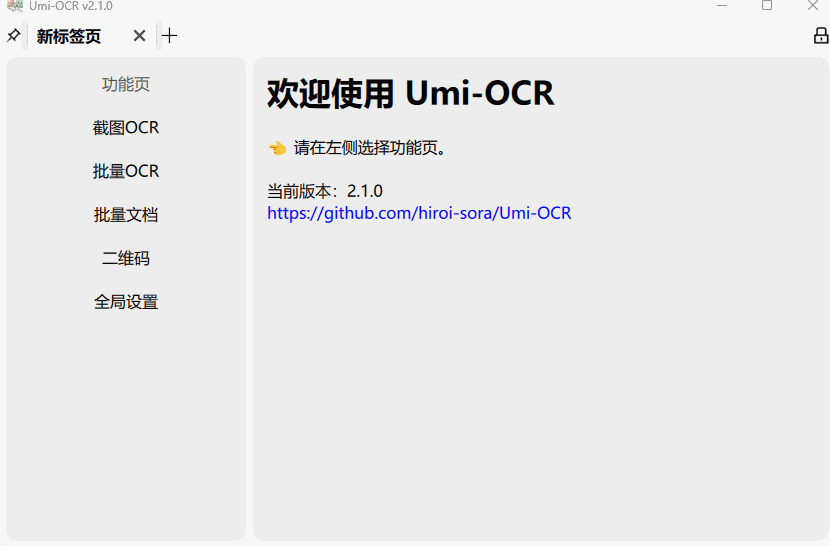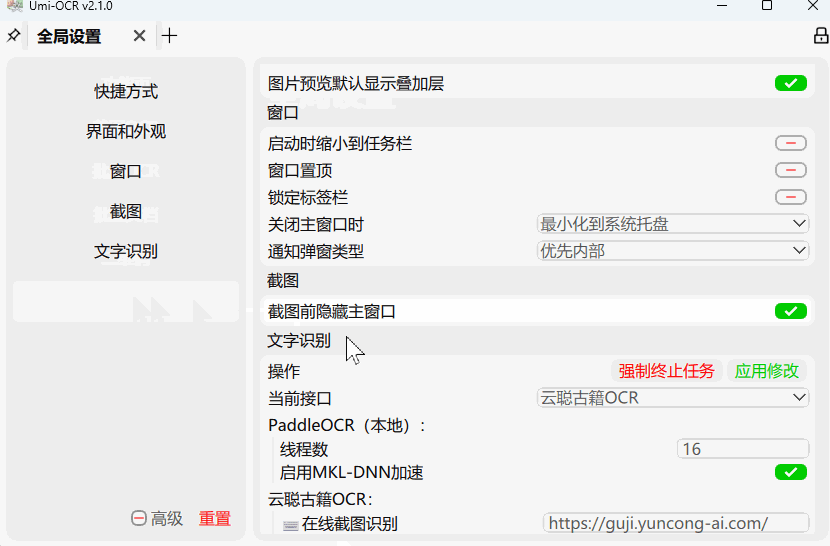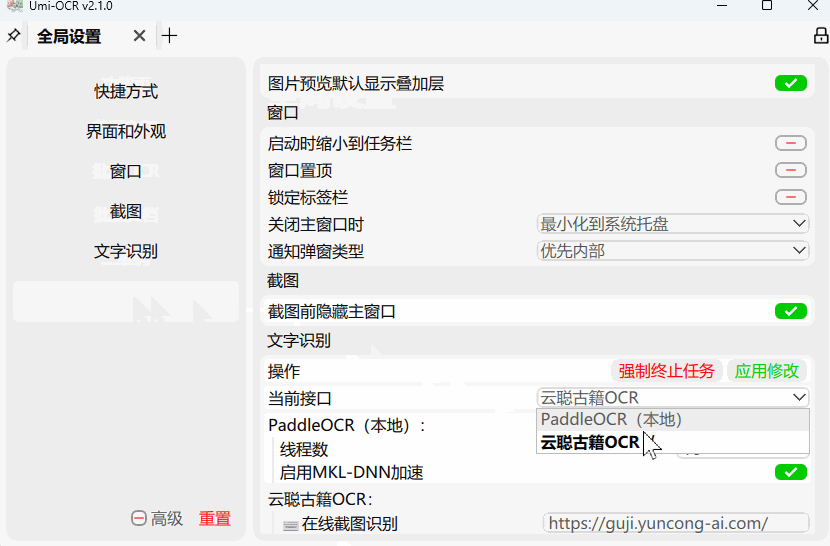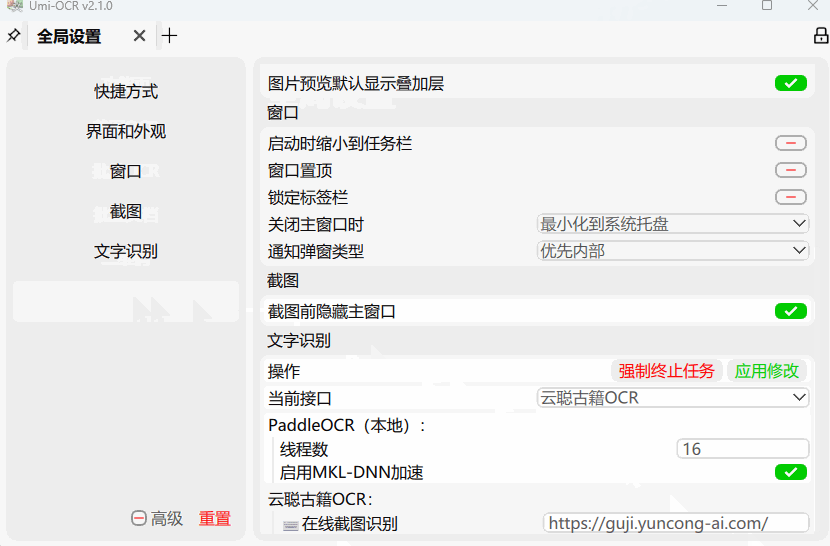
如果您已经安装过Umi-OCR,需要您手动切换接口,请参考下图,全局设置→当前接口 。
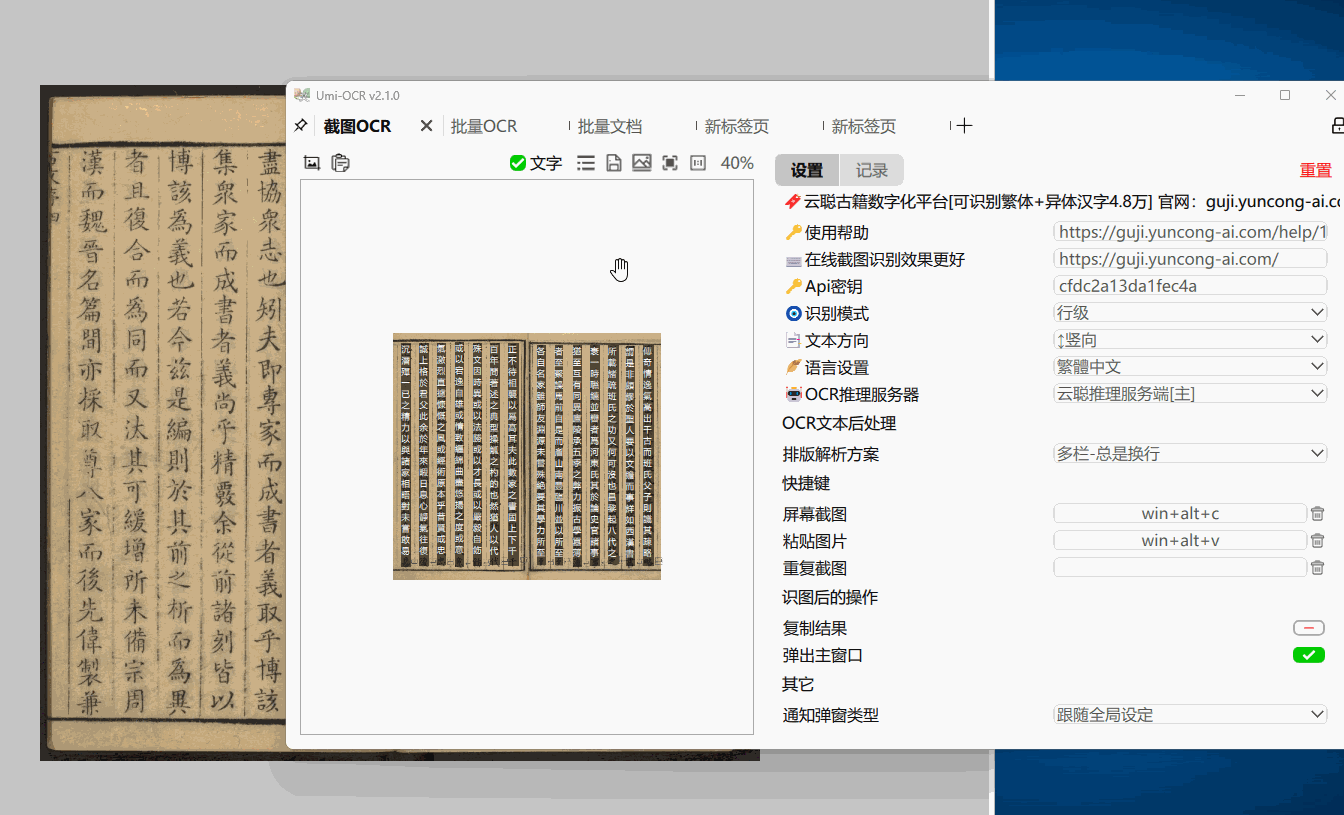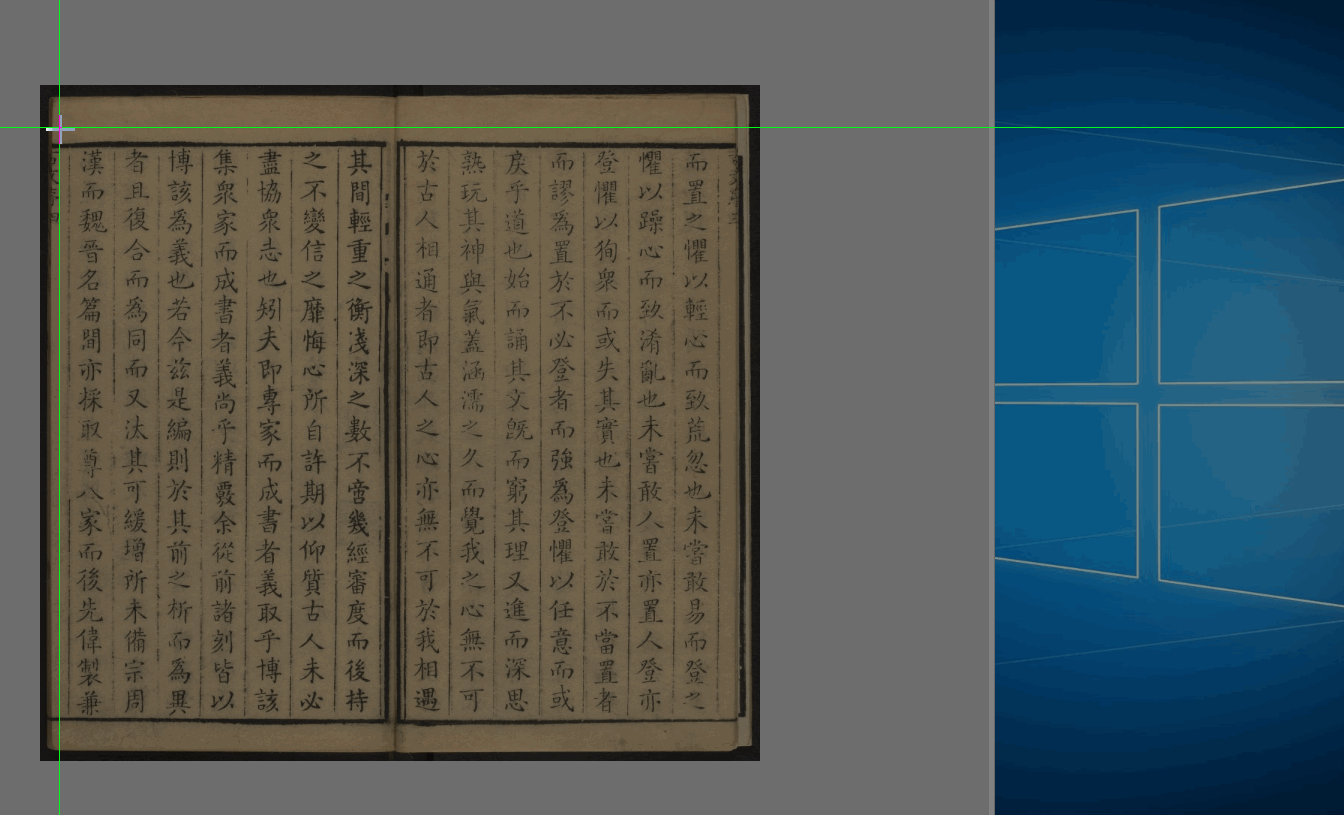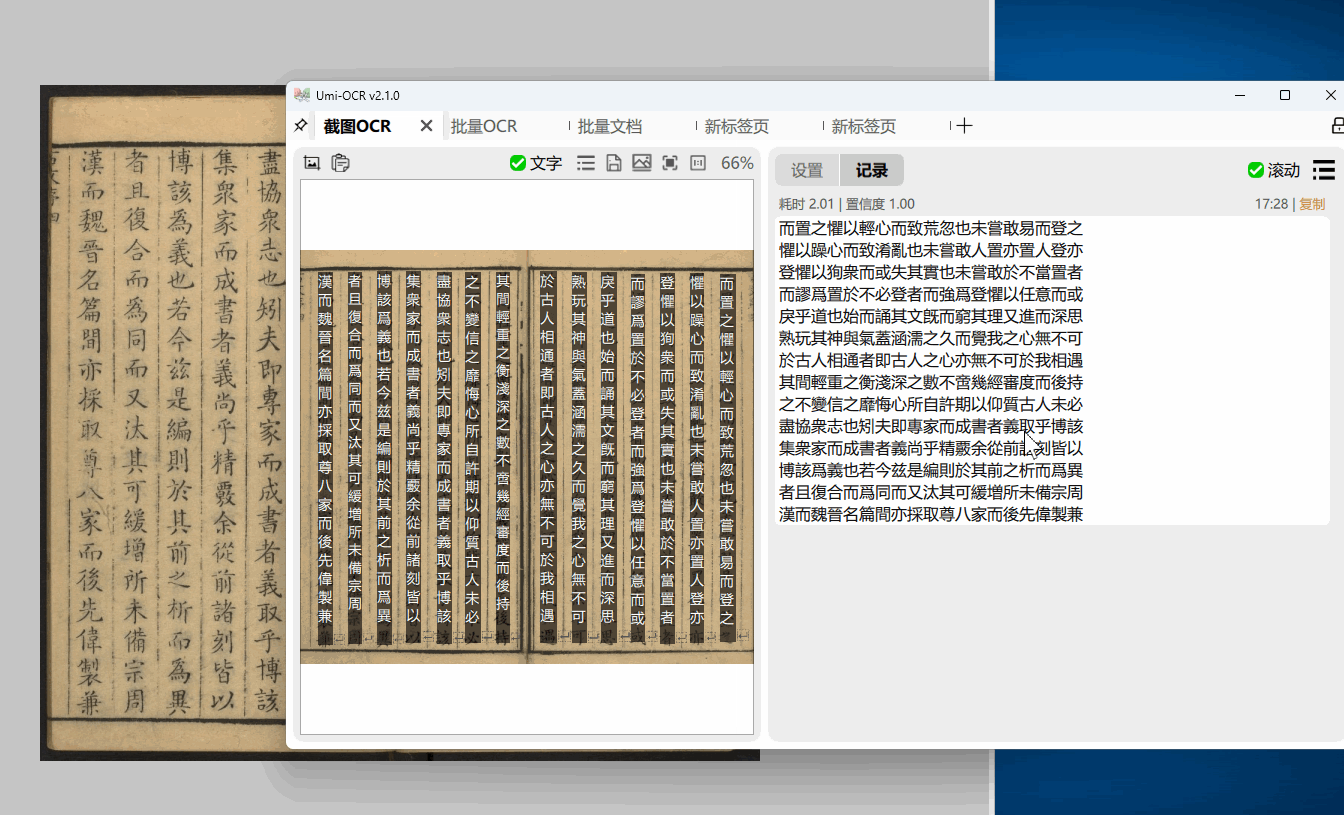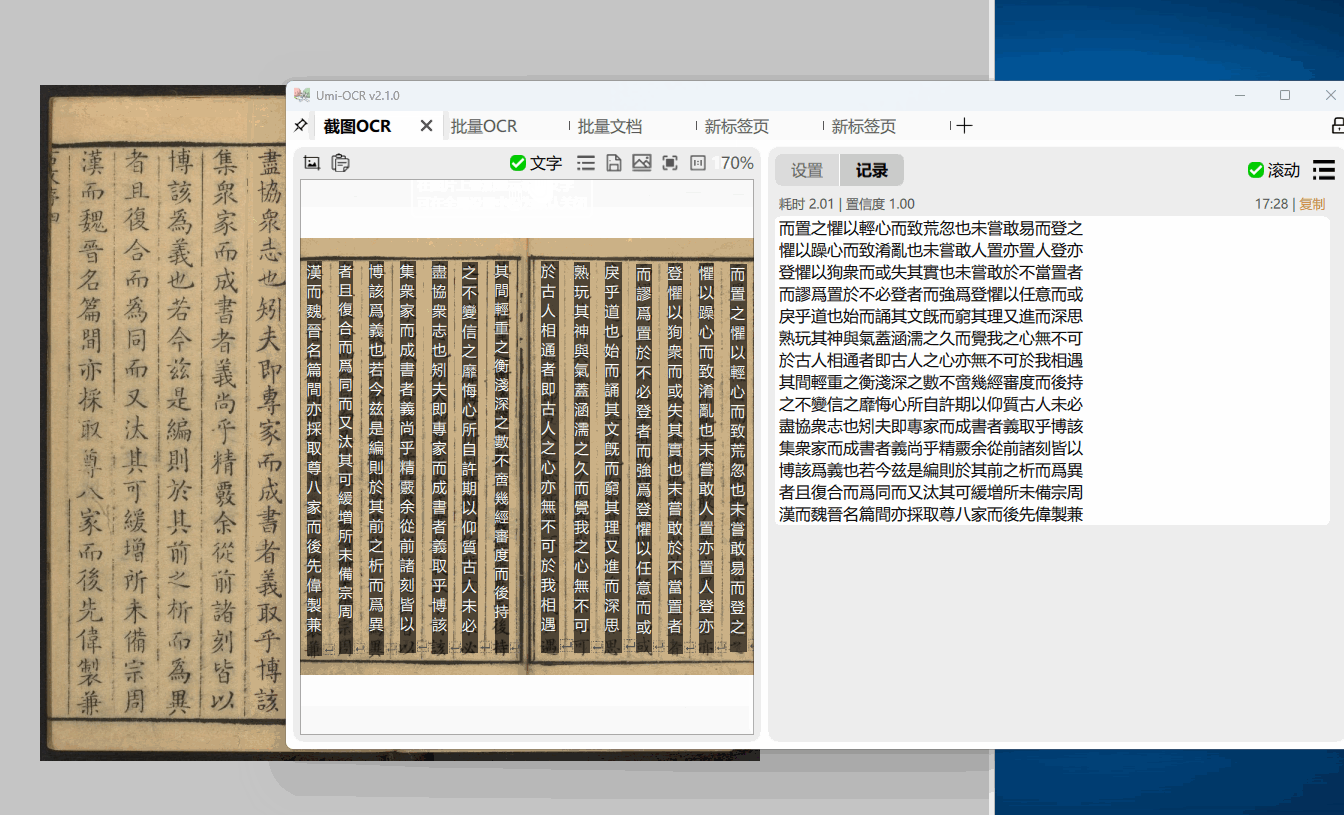
截图OCR
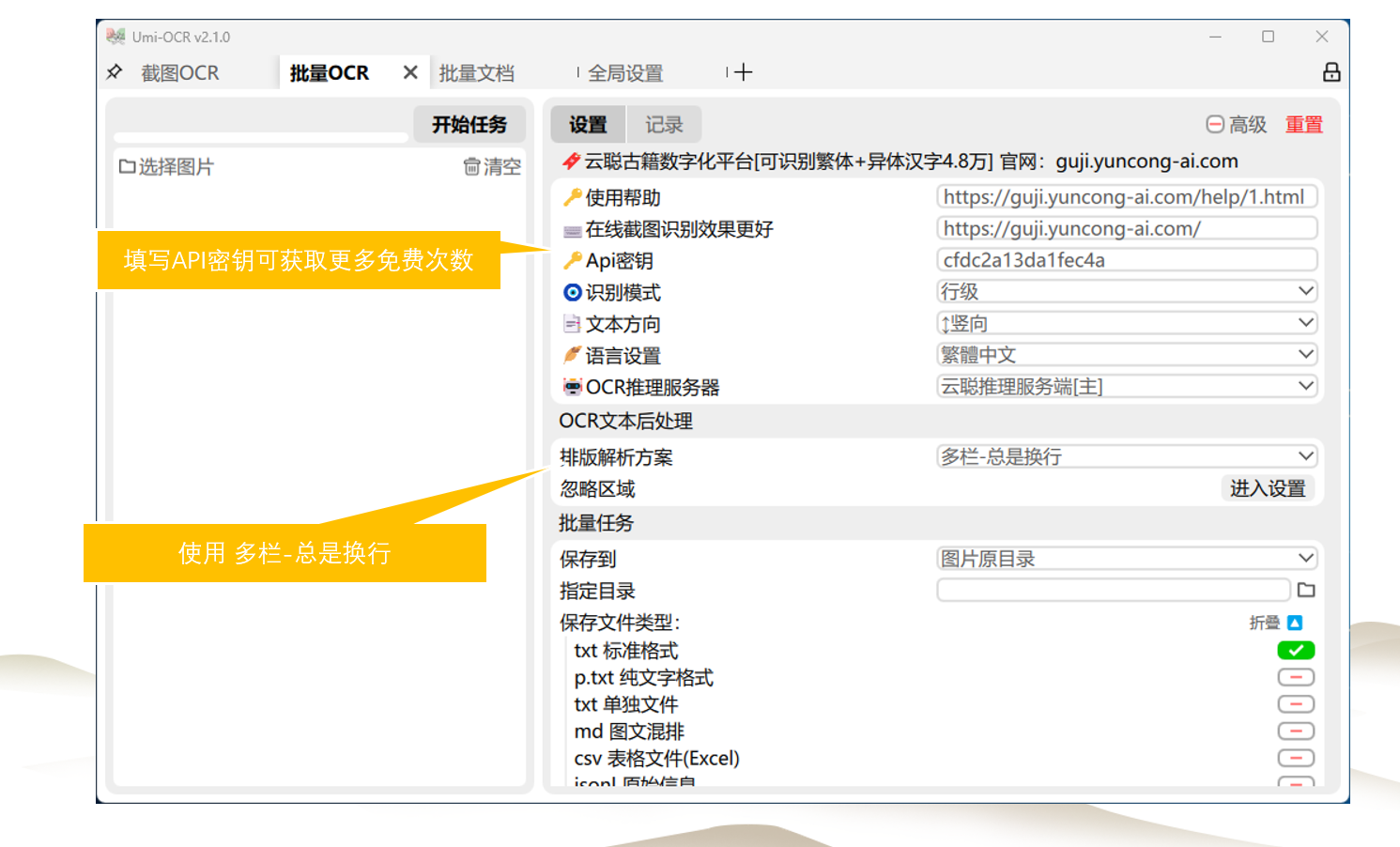
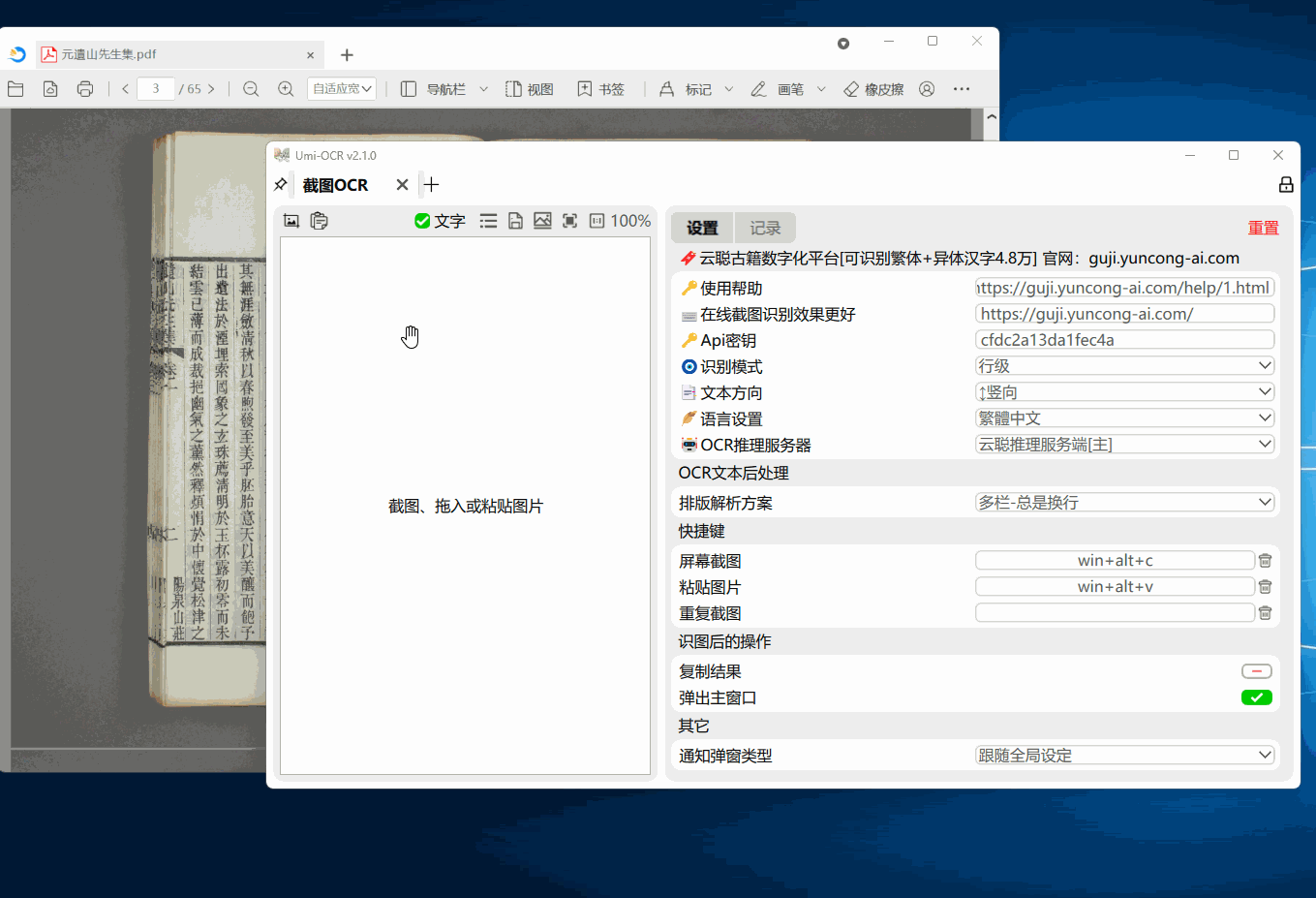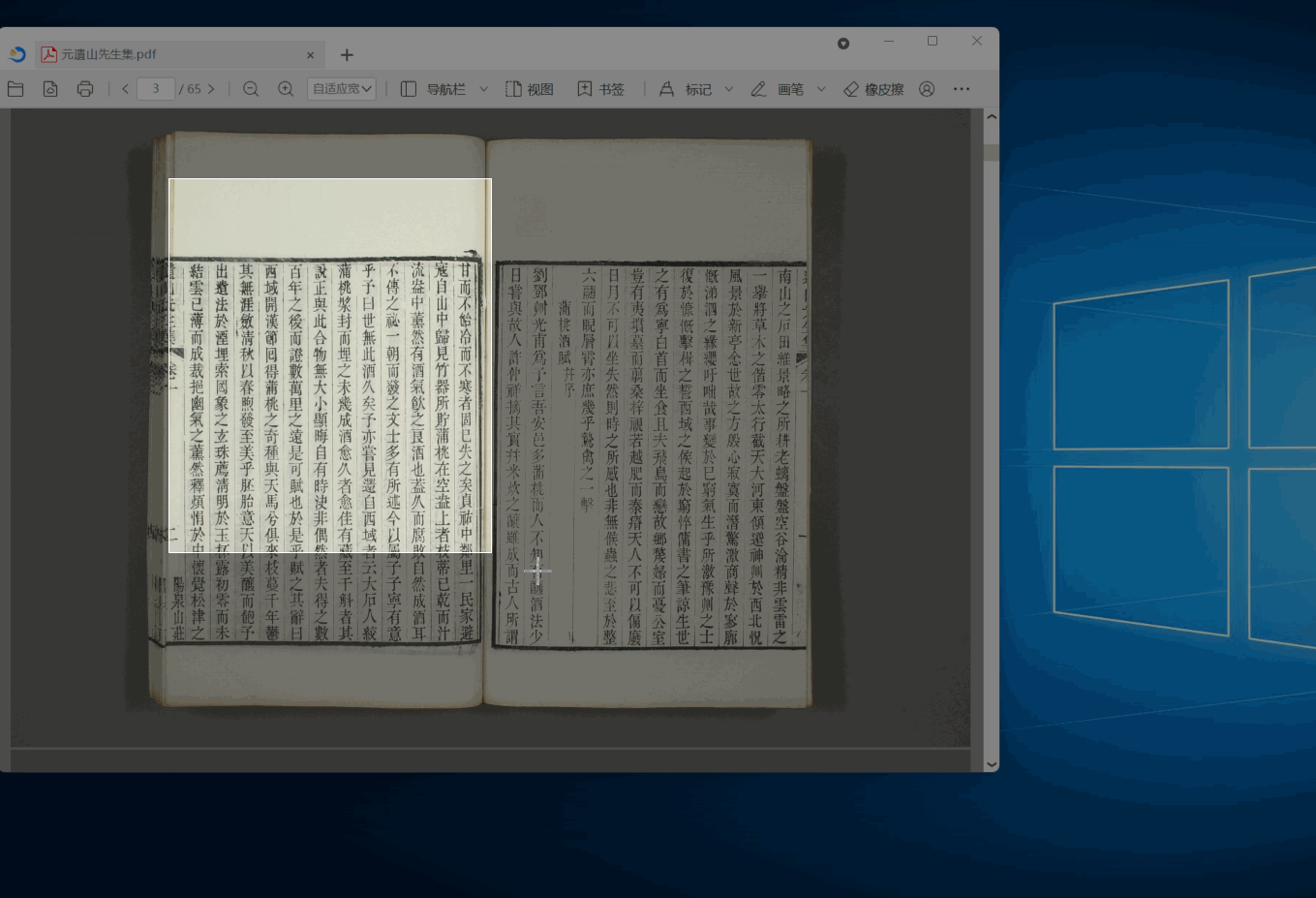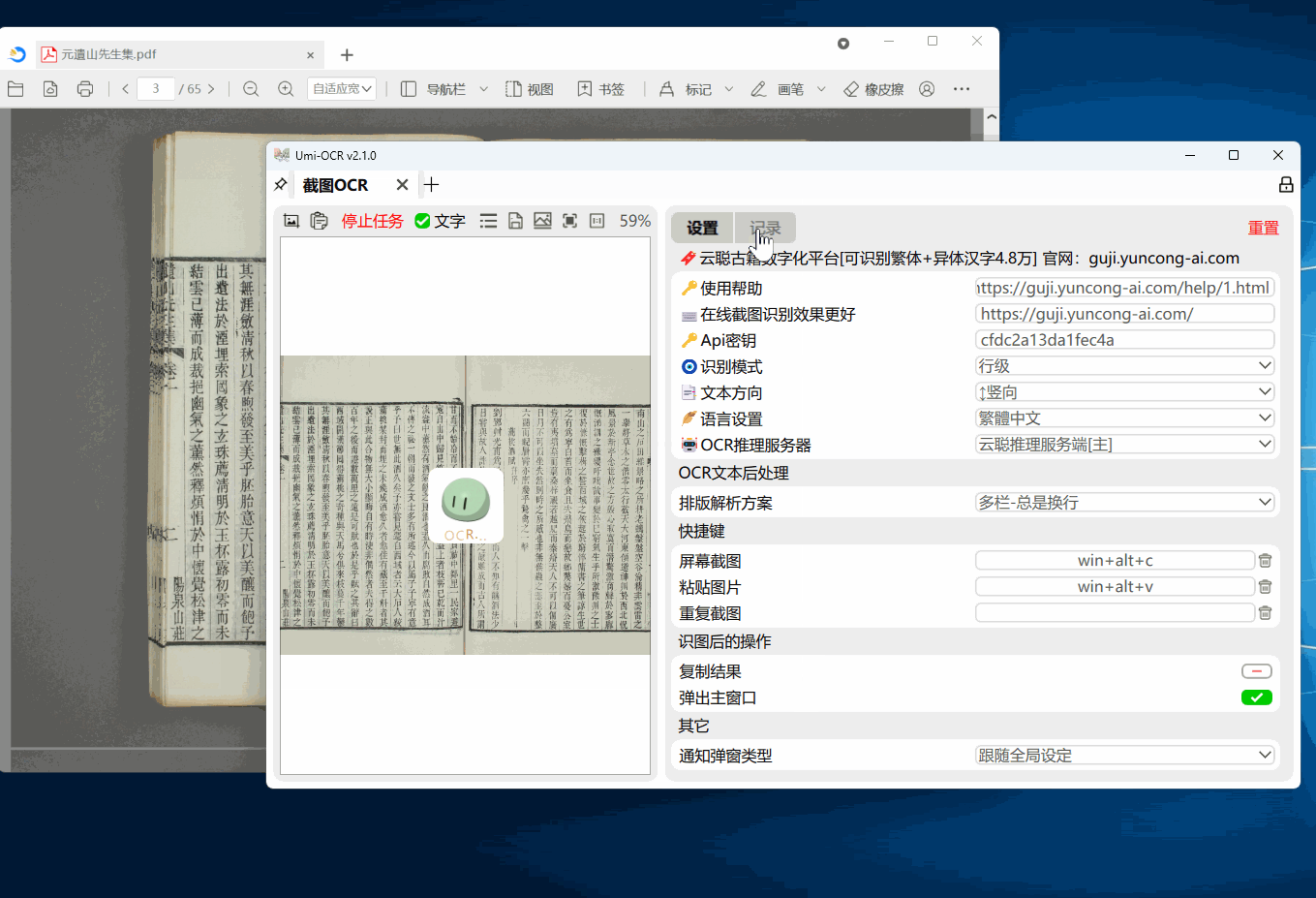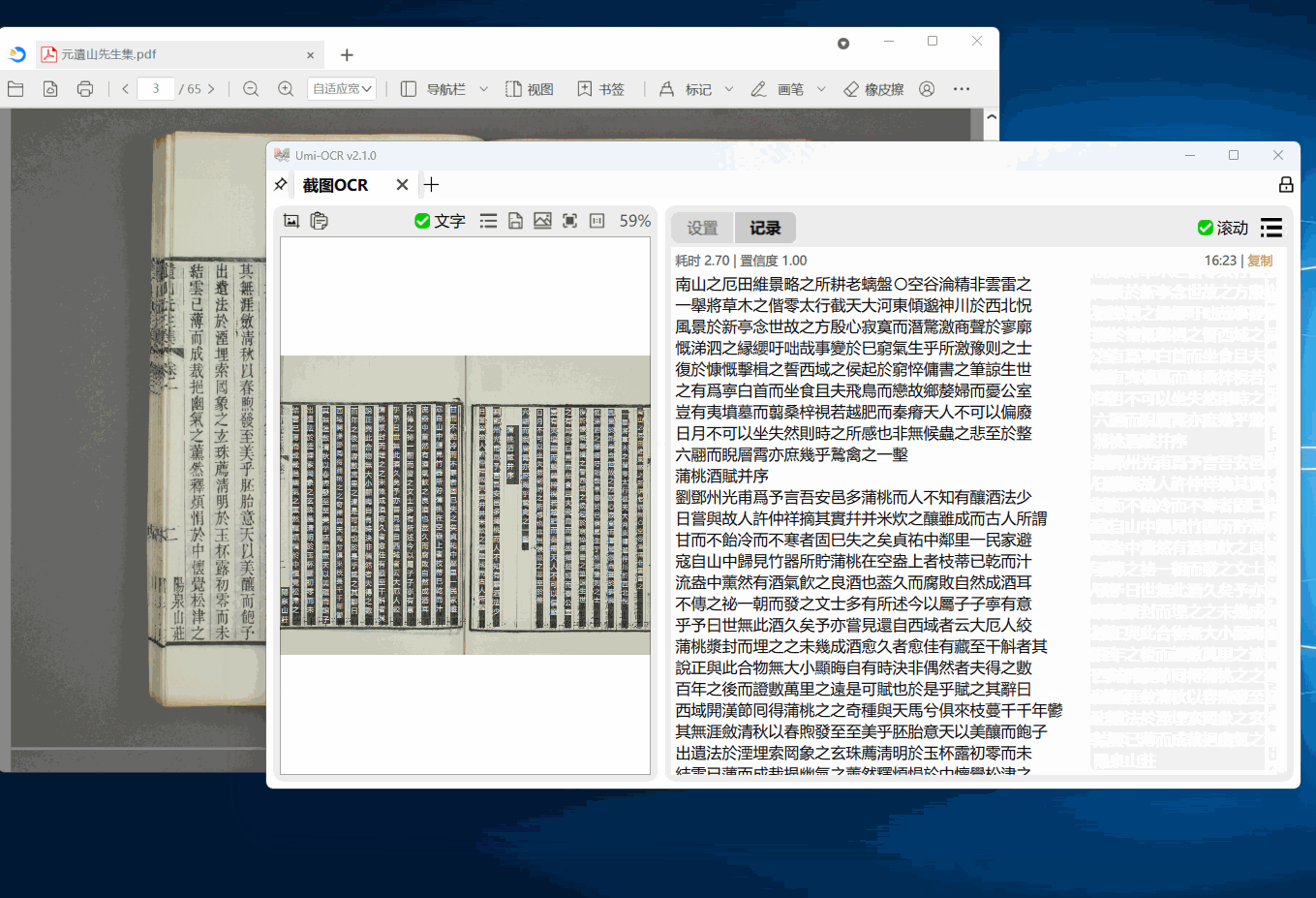
打开这一页后,就可以用快捷键唤起截图,识别图中的文字。
左侧的图片预览栏,可直接用鼠标划选复制。
右侧的识别记录栏,可以编辑文字,允许划选多个记录复制。
也支持在别处复制图片,粘贴到Umi-OCR进行识别。
批量OCR
在使用批量OCR之前,强烈建议先注册云聪OCR会员,并填写API密钥。如果您有大量的古籍需要识别,建议先充值购买积分 👉️👉️ 【积分充值】。
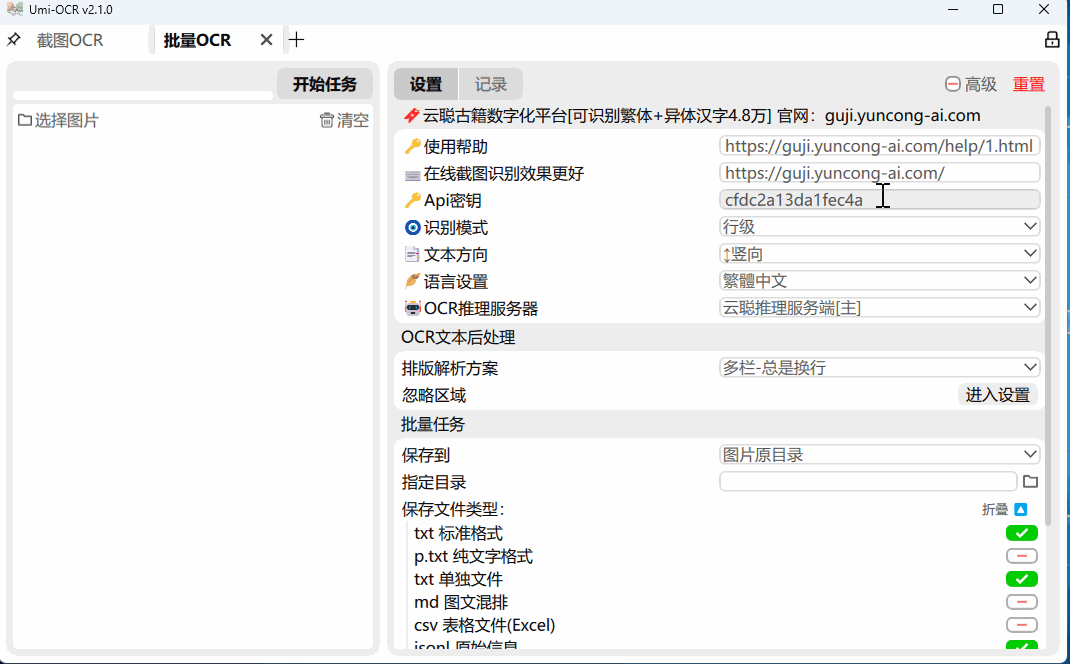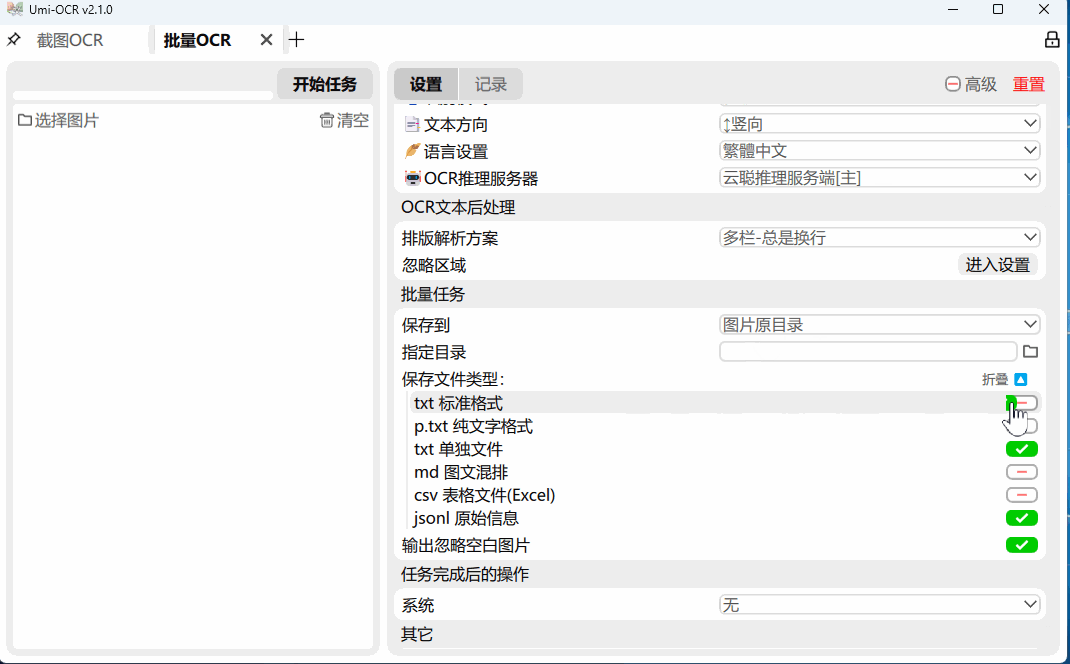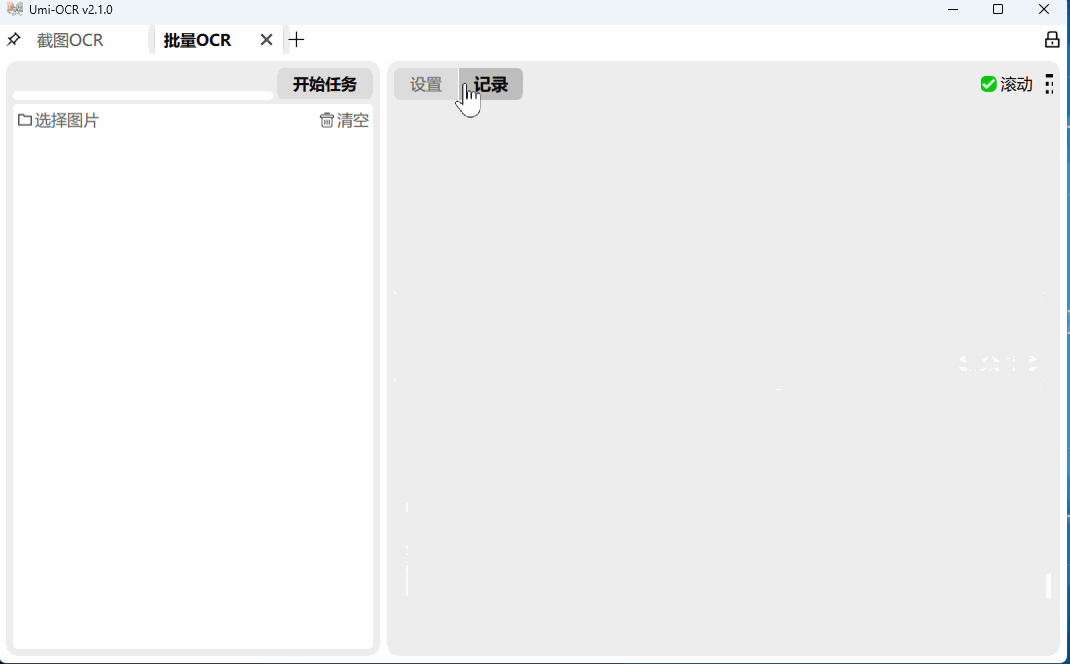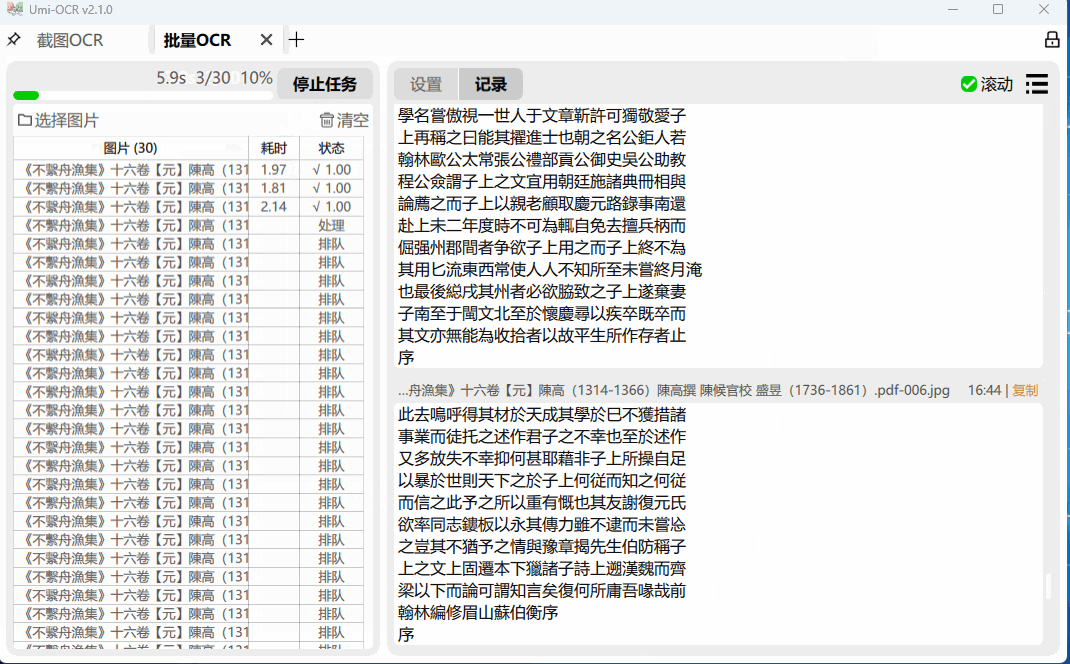
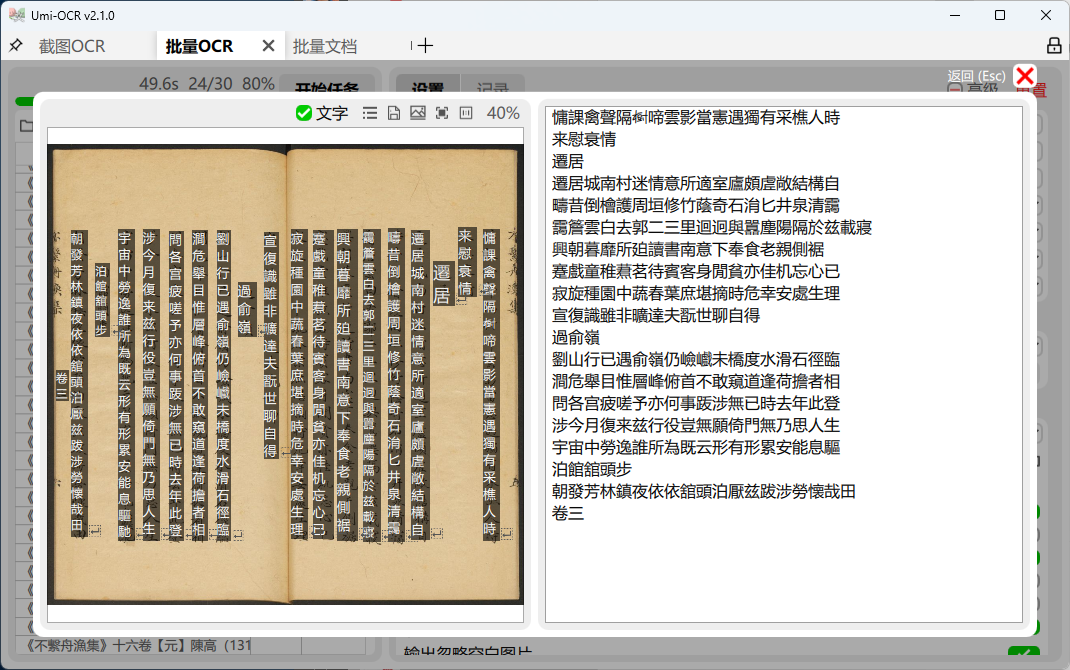
这一页用于批量导入本地图片进行识别。
支持格式:jpg, jpe, jpeg, jfif, png, webp, bmp, tif, tiff。
保存识别结果的支持格式:txt, jsonl, md, csv(Excel)。
与截图OCR一样,支持文本后处理功能,整理OCR文本的排版和顺序。
支持任务完成后自动关机/待机。
忽略区域
关于 OCR文本后处理 - 忽略区域: 批量OCR中的一种特殊功能,适用于排除图片中的不想要的文字。
- 在批量识别页的右栏设置中可进入忽略区域编辑器。
- 如上方样例,图片顶部和右下角存在多个水印 / LOGO。如果批量识别这类图片,水印会对识别结果造成干扰。
- 按住右键,绘制多个矩形框。这些区域内的文字将在任务中被忽略。
- 请尽量将矩形框画得大一些,完全包裹住水印所有可能出现的位置。
古籍PDF批量识别
在使用文档批量识别之前,强烈建议先注册云聪OCR会员,并填写API密钥。如果您有大量的古籍需要识别,建议先充值购买积分 👉️👉️ 【积分充值】。
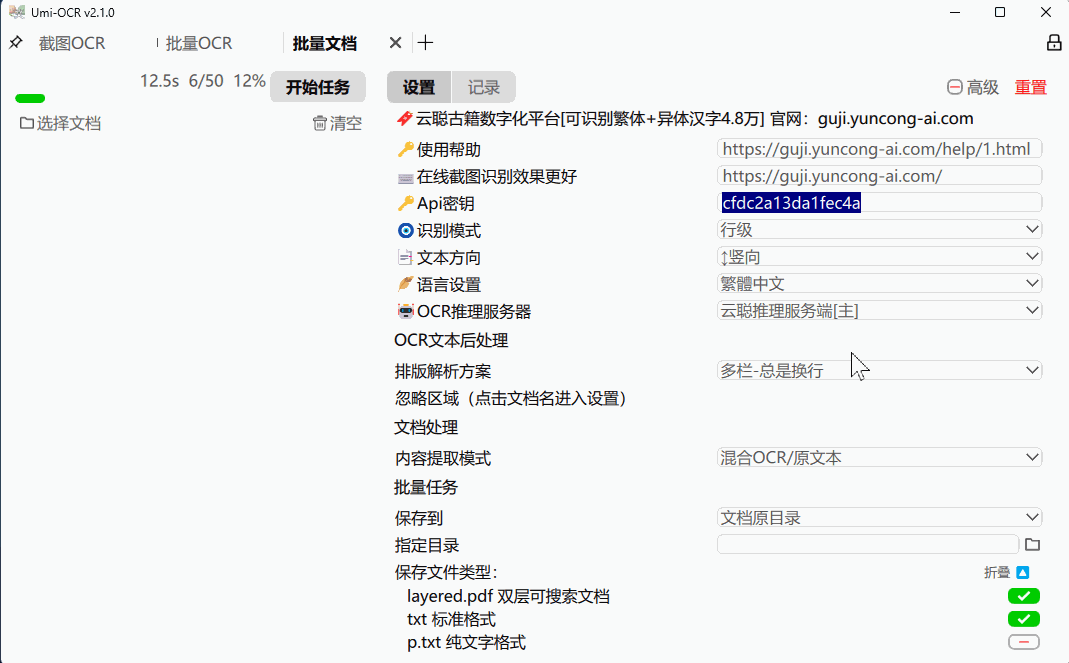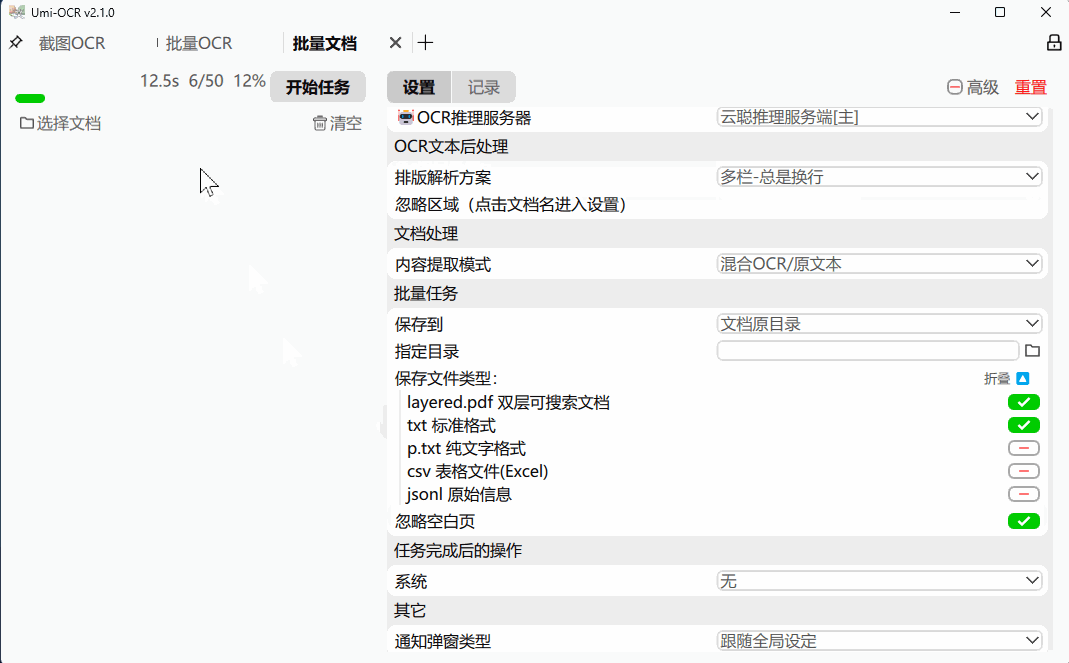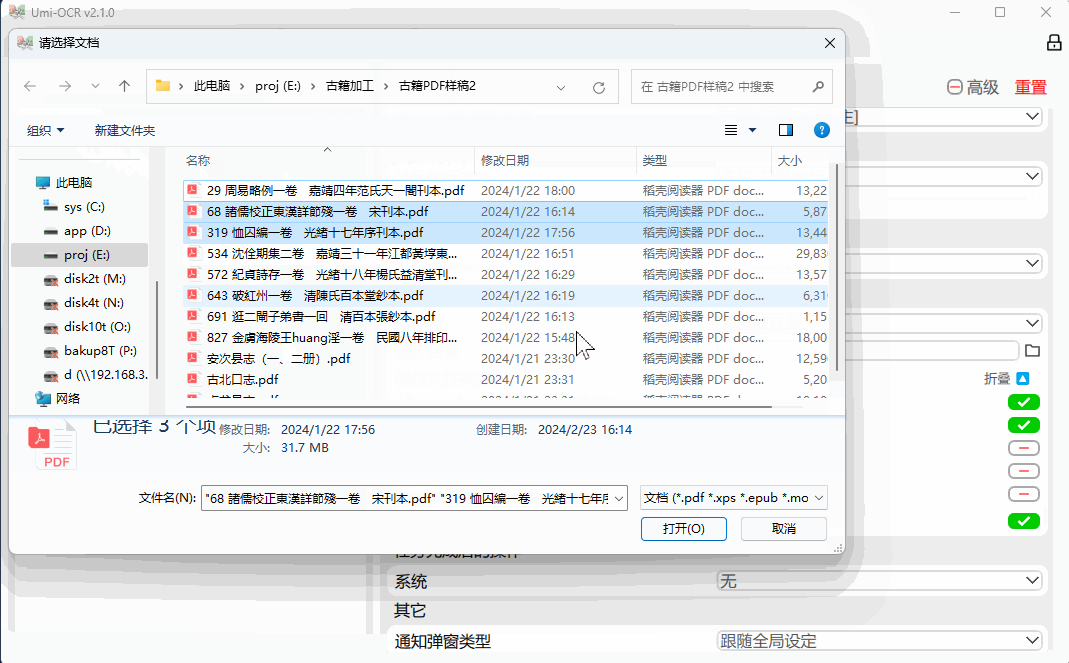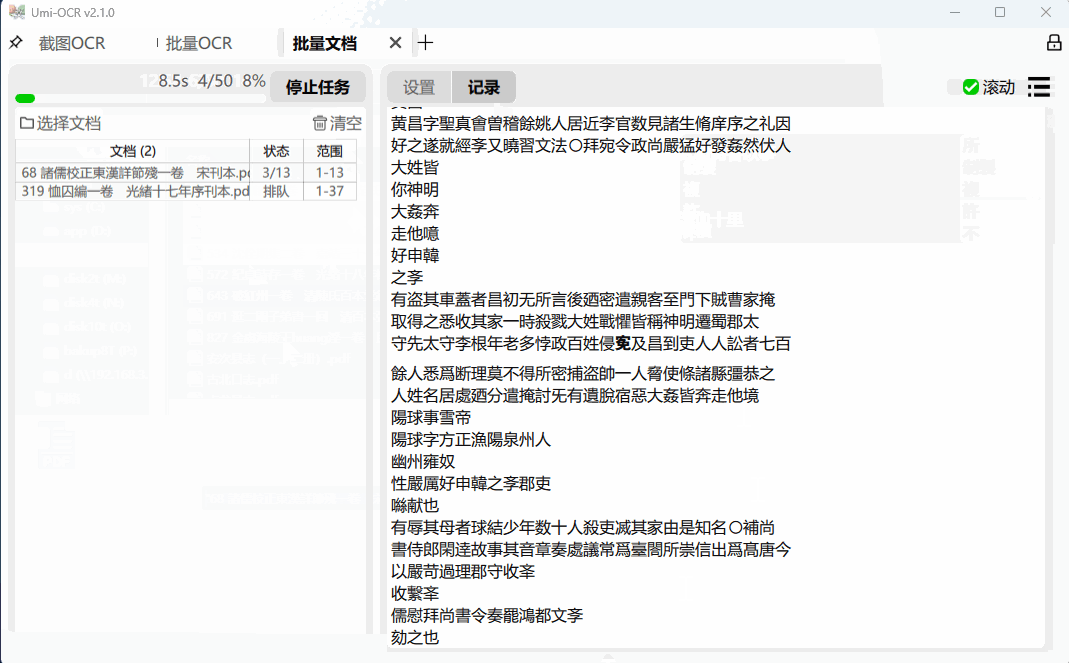
支持格式:pdf, xps, epub, mobi, fb2, cbz。
对扫描件进行OCR,或提取原有文本。可输出为 双层可搜索PDF 。
支持设定 忽略区域 ,可用于排除页眉页脚的文字。
可设置任务完成后 自动关机/休眠 。
API密钥获取
如果您有大量的古籍报刊识别需求,想获得更多使用次数,建议 注册会员 在客户端设置 API密钥后使用。
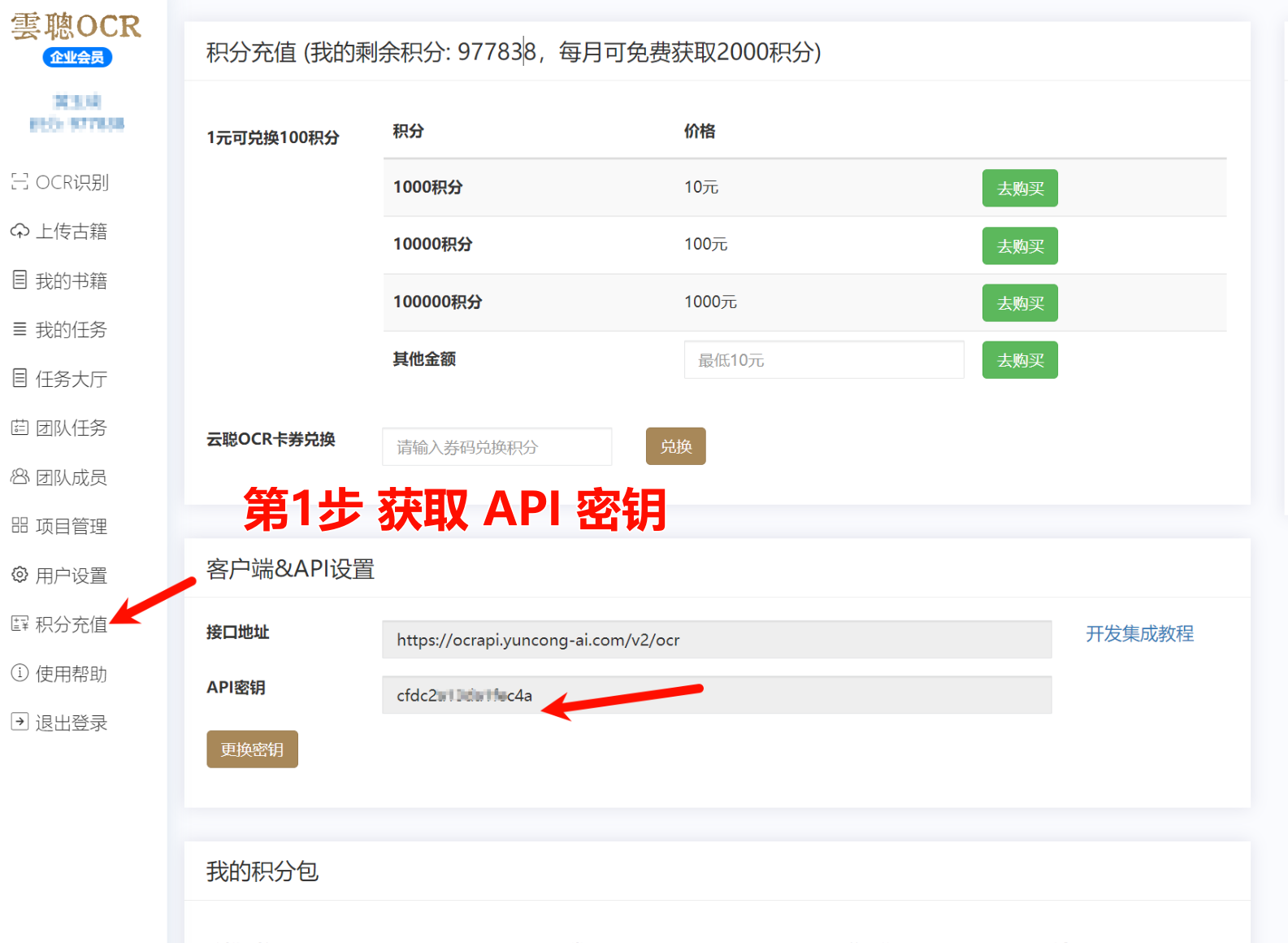
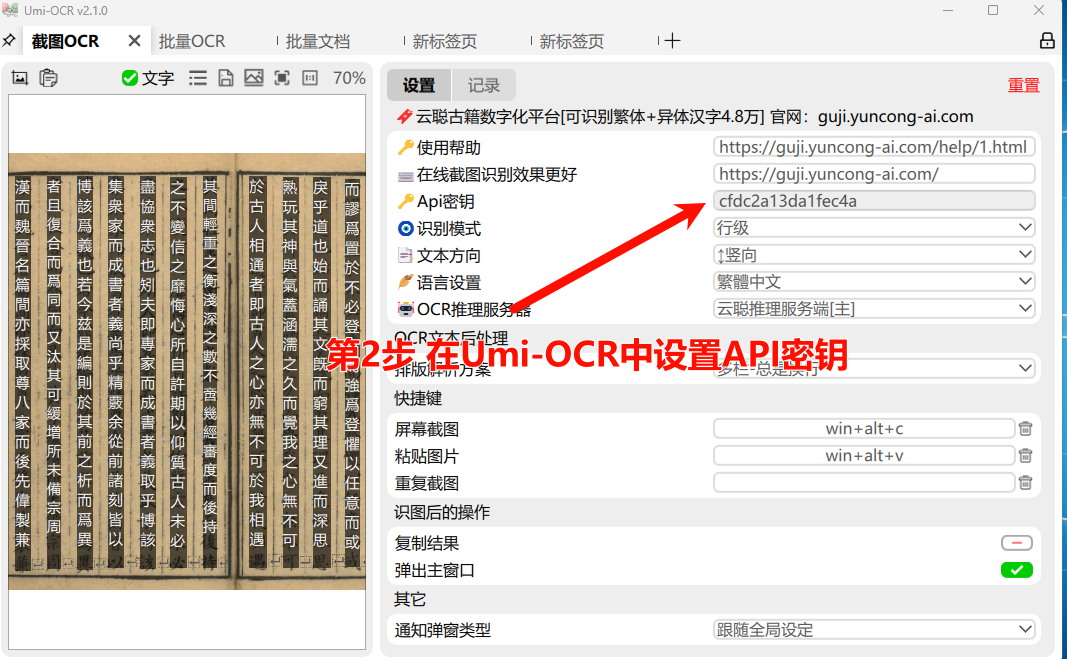
Umi-OCR 文字识别工具 基于MIT开源协议,如果您需要更多功能,请参考使用教程:https://gitee.com/mirrors/Umi-OCR
