文本校对流程:逐字精校,效率卓越
云聪OCR提供两种文字校对方式,横排逐字校对、集合逐字校对两种方式。
一、横版逐字校对
云聪OCR精校工厂支持将竖版繁体文字转换为横版繁体文字,在识别结果区域中,通过人工逐字逐句比较识别结果与原始图像,单个文字上下一对一进行逐字校对,支持全程快捷键键盘操作,符合现在的阅读习惯,大大提高校对效率。
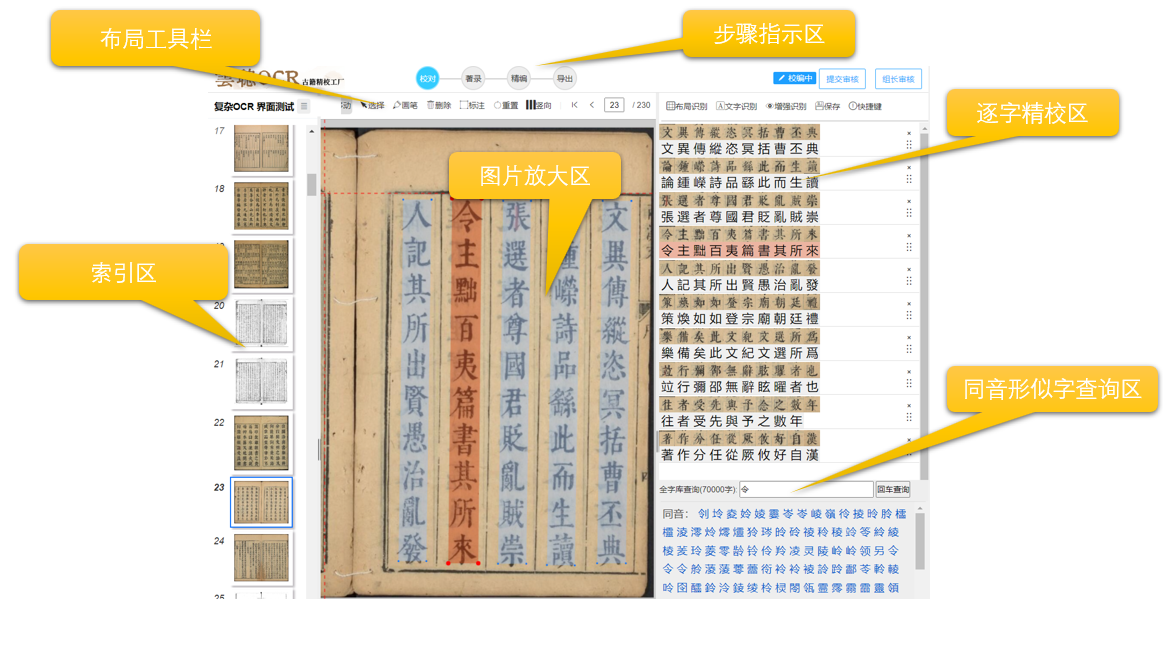
| 快捷键 | 功能说明 |
|---|---|
| ESC键 | 光标返回到逐字精校区 |
| ←
→
左右箭头 | 选中前、后 字 |
| ↑ ↓ 上下箭头 | 选中上、下行 |
| HOME键 | 选中当前行第一个字 |
| END 键 | 选中当前行最后个字 |
| Ctrl + S 键 | 保存校对结果 |
| Ctrl + →键 | 保存校对结果,并跳转到下一页 |
| Ctrl + ←键 | 保存校对结果,并跳转到上一页 |
| Enter 回车键 | 查询当前选中字的同音字和形似字 |
| Alt + 数字键 或 鼠标点击 | 同音字和形似字 替换 当前选中字 |
二、集字校对
集字逐字校对是指,针对多本古籍或者某个项目的识别结果,通过大数据统计的方式,将相同的文字对应的图像显示集合在一起统一校对,这样大部分识别正确的字跟小部分识别错误的字放在一起,非常容易发现错误的地方,校对效率较高。
集字校对仅对企业用户开放,如需使用请扫描下方客服二维码。

三、说说经验(三校法)
三校法是指,一校使用横排逐字校对,先把文本对齐,可达到95%以上的正确率;然后进行二校,二校使用集字校对,矫正错误识别并标记可疑文字,可达到99%的正确率;三校是对可疑文字所在的页面再进行一次横排逐字校对,可达到99.8%的正确率。三校后,基本可以满足出版以及国家相关规定要求。
对于版面规范、文字规整、识别率较高的古籍文档,可以使用集合逐字校对的方式;
对于图像质量较差、OCR识别结果不佳的古籍文档建议采用横排逐字校对+集合逐字校对相结合的方式,第一次校对使用横排逐字校对快速粗校的方式,做到文字对齐即可,然后第二次校对使用 集合逐字校对 的方式,力求对每个文字进行纠错,这样就能得到尽可能低的错误率以及较好的识别结果。
四、基本技能
云聪OCR不同版面校对方法示例
一、基本技能
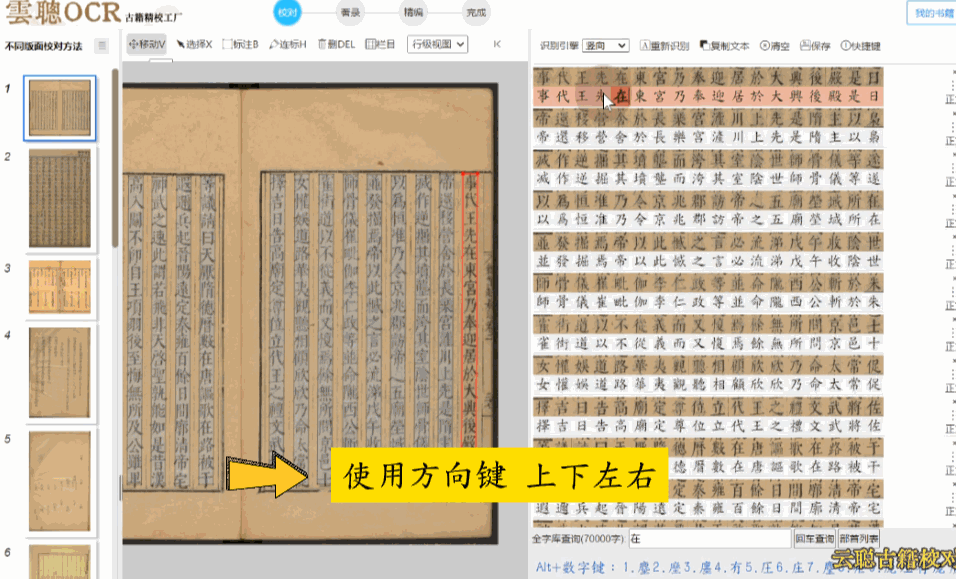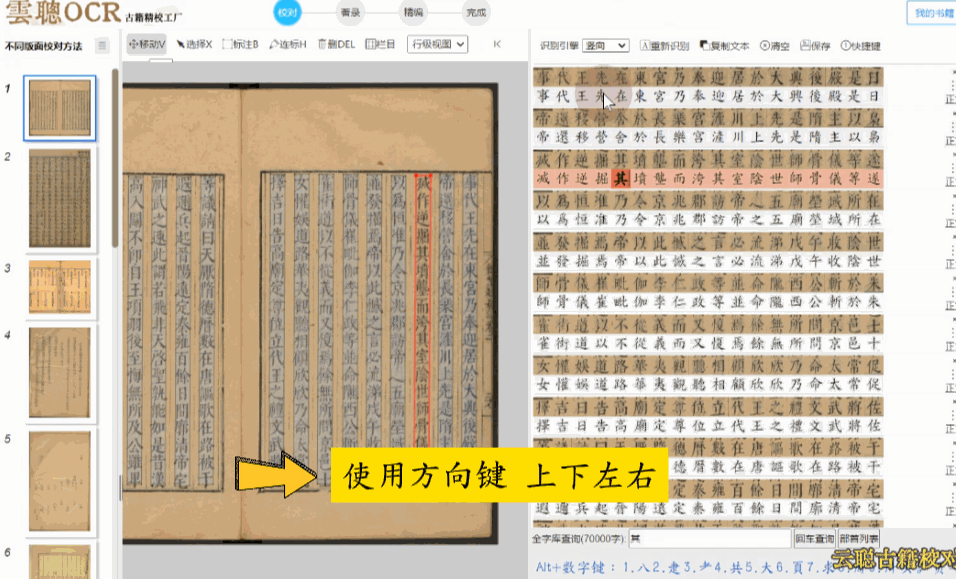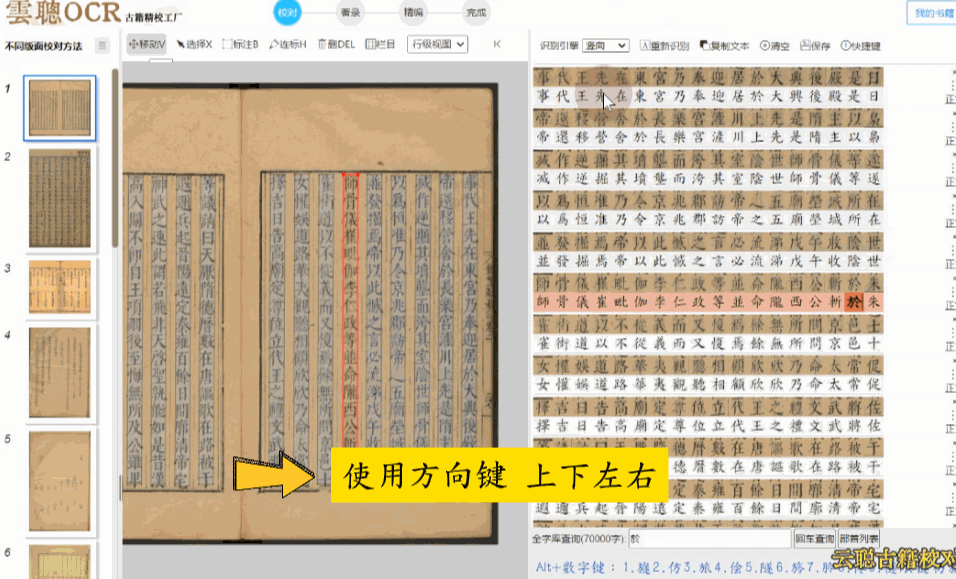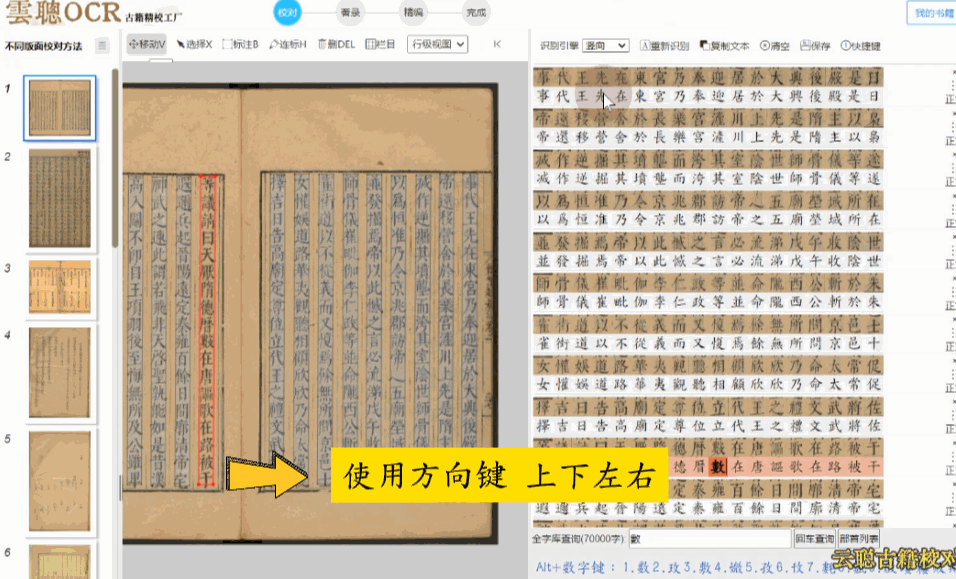
1、逐字校对
使用方向键上下左右快速逐字校对,配合Alt+数字键快速纠正。
2、语序调整
按住每行末尾的拖拽按钮,或者使用Ctrl+上下方向键,可以快速实现语序调整。
3、划词识别
支持对古籍文本区块进行鼠标划词,即刻识别!
4、区块调整
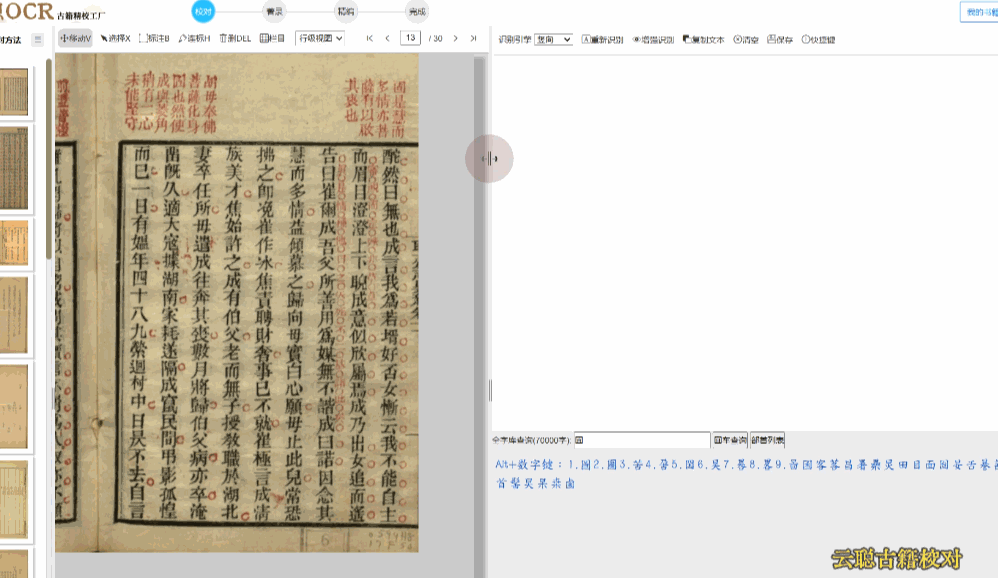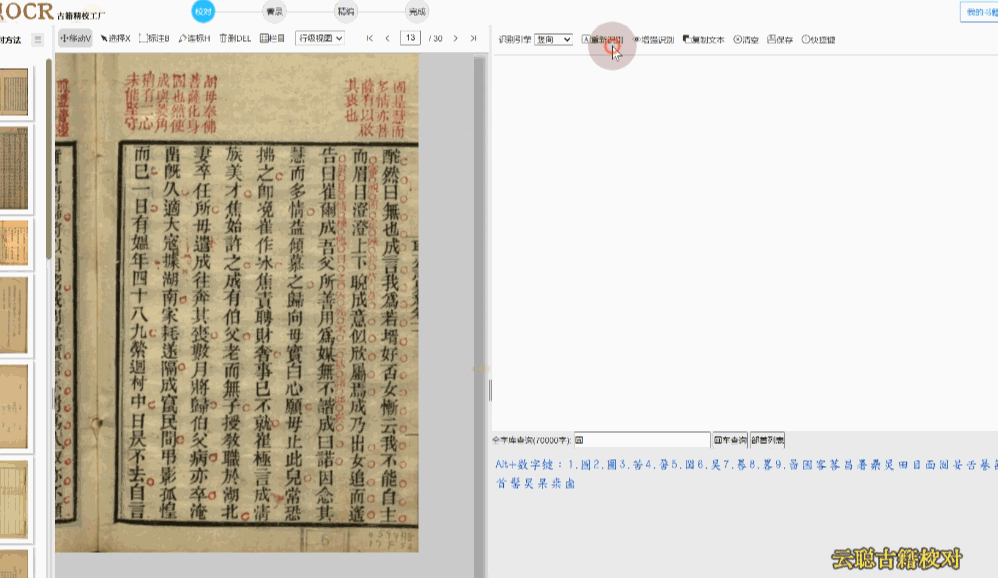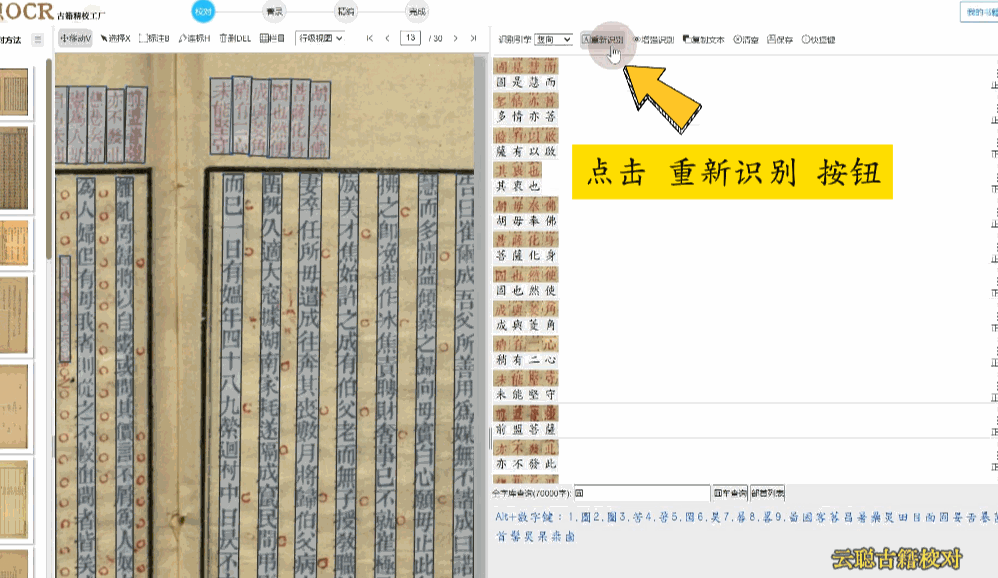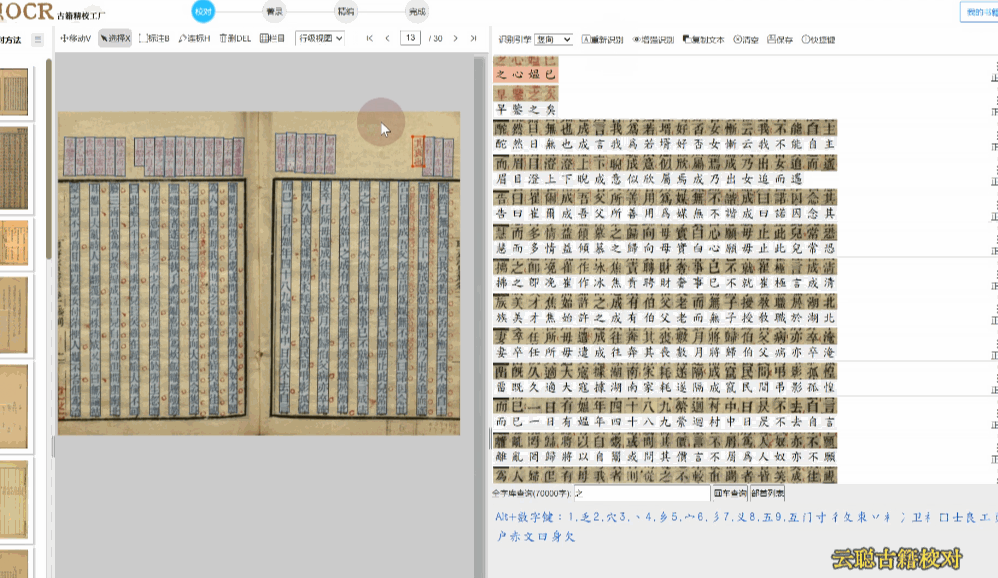
鼠标点击选中文本区块,可对区块位置大小进行调整校对,双击区块即可重新识别。
5、文本标注
点击每行末尾的标注按钮,可设置当前古籍文字类型,支持标题、正文、天头、地脚、小注等5种标注类型,可满足大部分出版行业要求。
6、栏目画块
针对族谱、家谱、县志、期刊、画报等有上下分层、左右分块的版面,可使用栏目画块的方式,规整段落,优化阅读顺序。
7、栏目标注
点击每行末尾的标注按钮,可设置当前古籍文字类型,支持标题、正文、天头、地脚、小注等5种标注类型,可满足大部分出版行业要求。
8、部首查词
7w简体、繁体、异体字任意查,支持查某个字的同音、形似字,也可以拆字查询。
五、校对实例
1、规整版面
版面整洁,无污垢,主要以印本、刻本为主,字体主要为明清的方体字和宋元以来的软字体,如颜体、柳体、赵体。
校对方法:基本不需要太多的校对,使用上下左右方向键快速逐字校验即可。
2、杂乱版面
注释较多,如行间的注释、连续划圈,会导致识别产生文本区块多标、区块位置不对的错误。
校对方法:删除多余文本区块,调整文字区块,重新双击识别
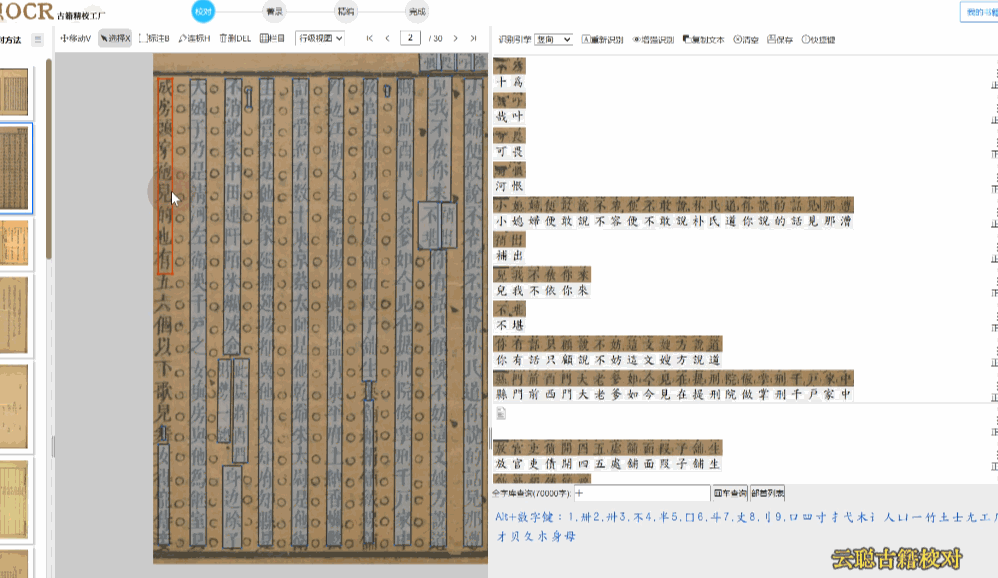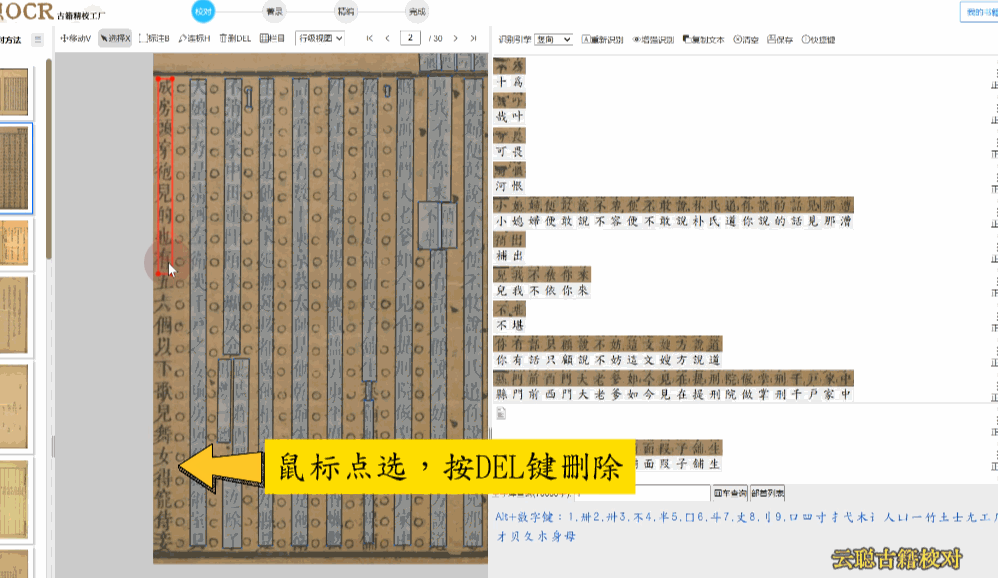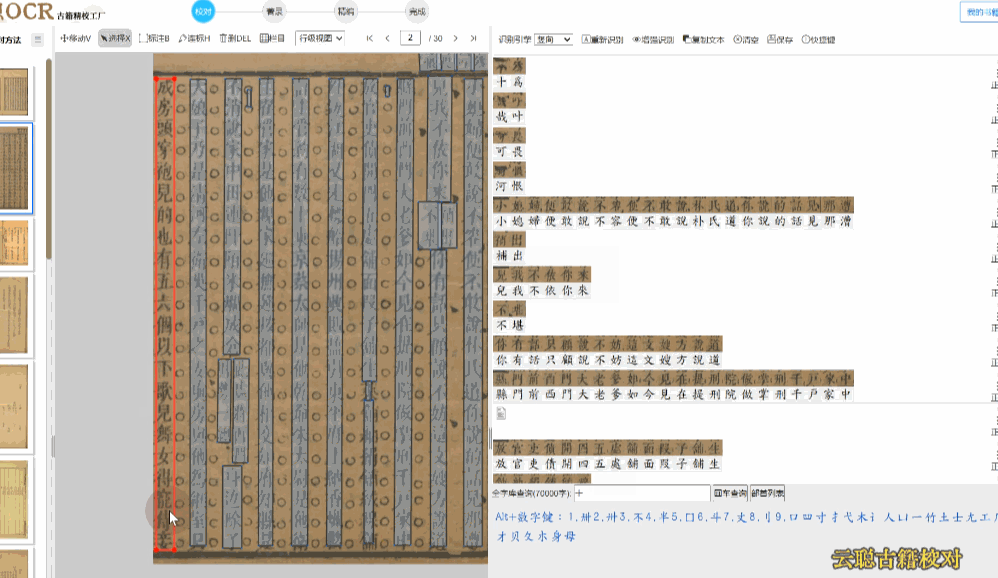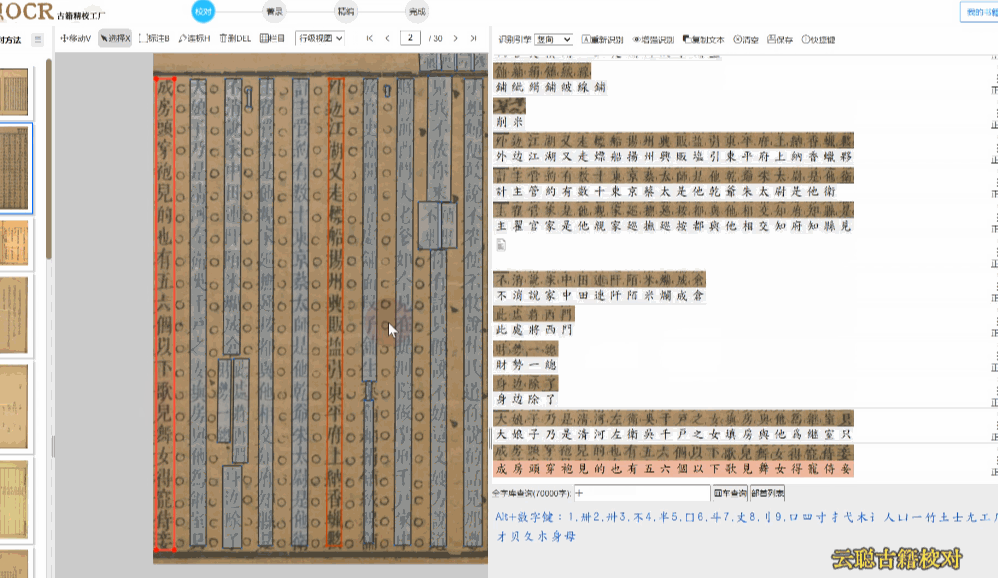
3、模糊版面
页面污损、模糊,比如页面上有褶皱、透光、透字、彩点、黑边等,都可能导致区块、文字识别异常。
校对方法:删除多余文本区块,调整文字区块,重新双击识别 或者 干脆清空所有识别结果,手动划词识别
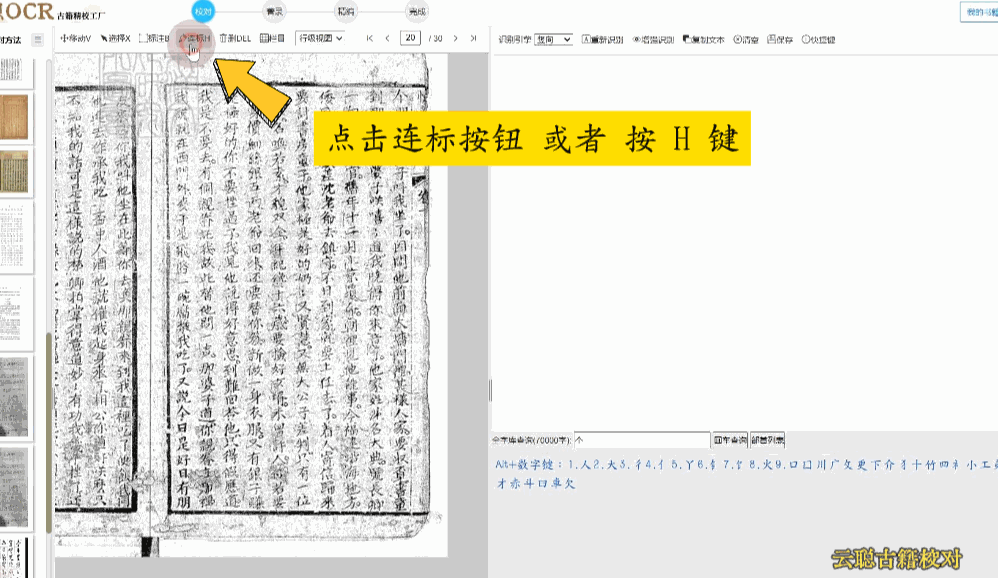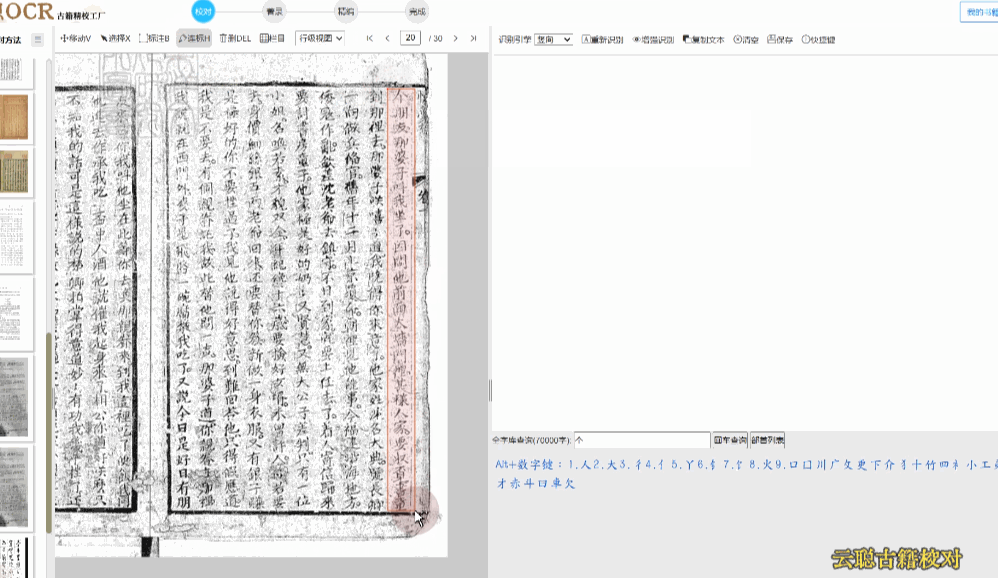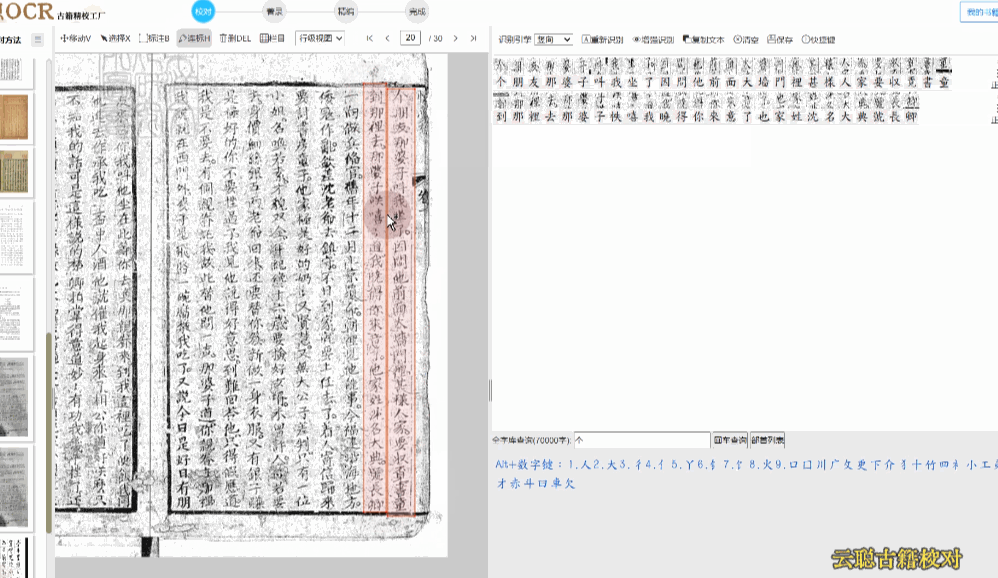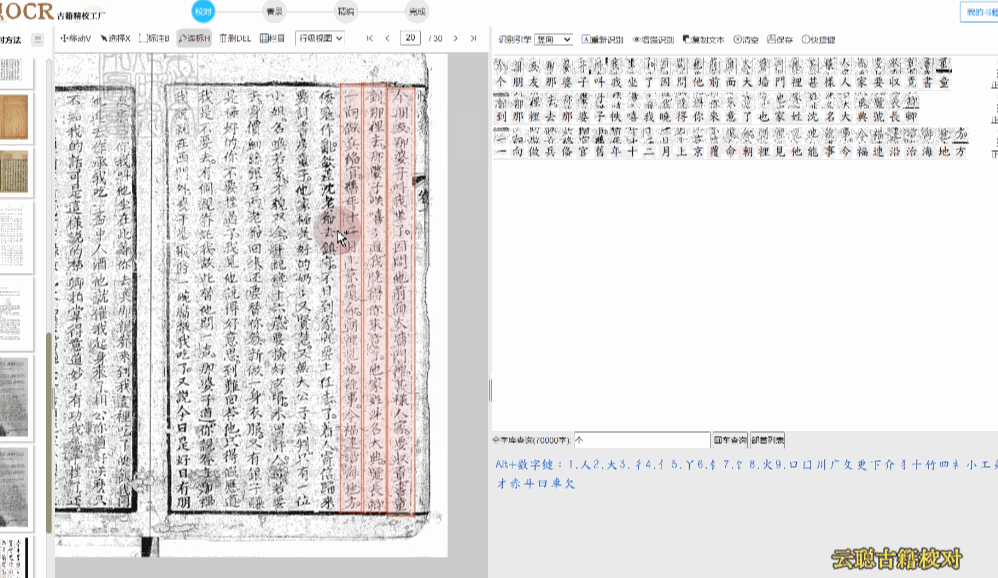
4、带天头地脚
古人为了加自己的注释,很多印本古籍都带有天头地脚,一般天头比地脚大一些。
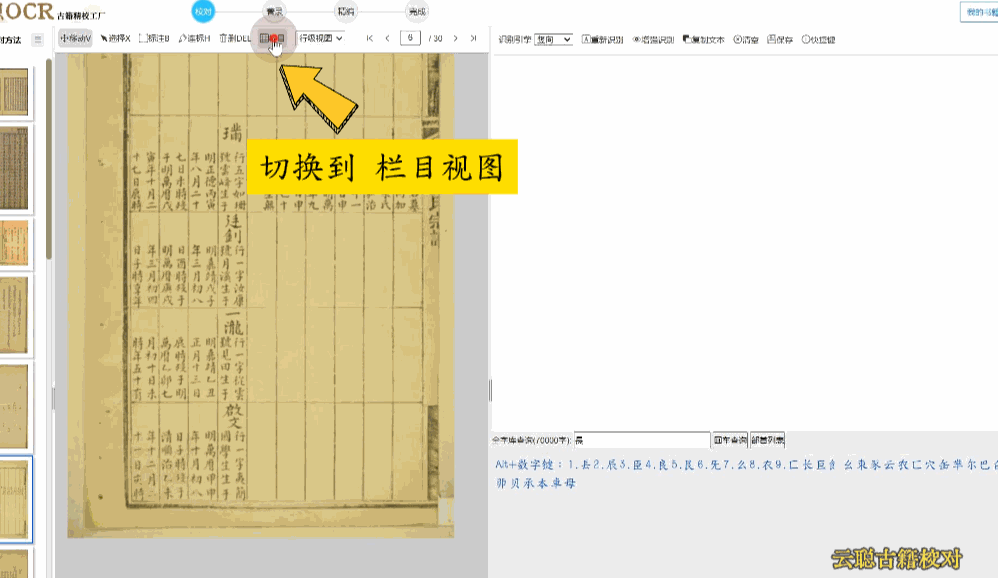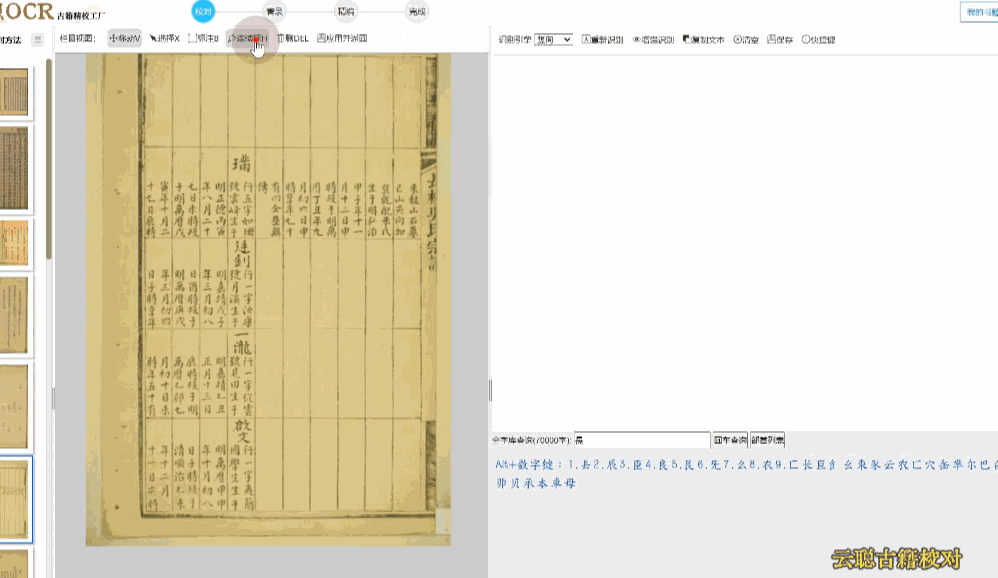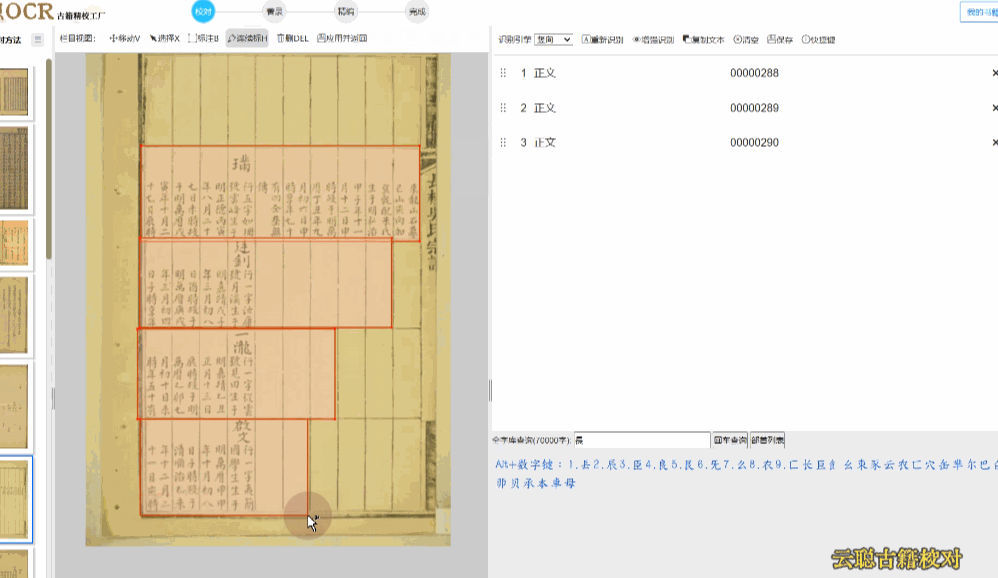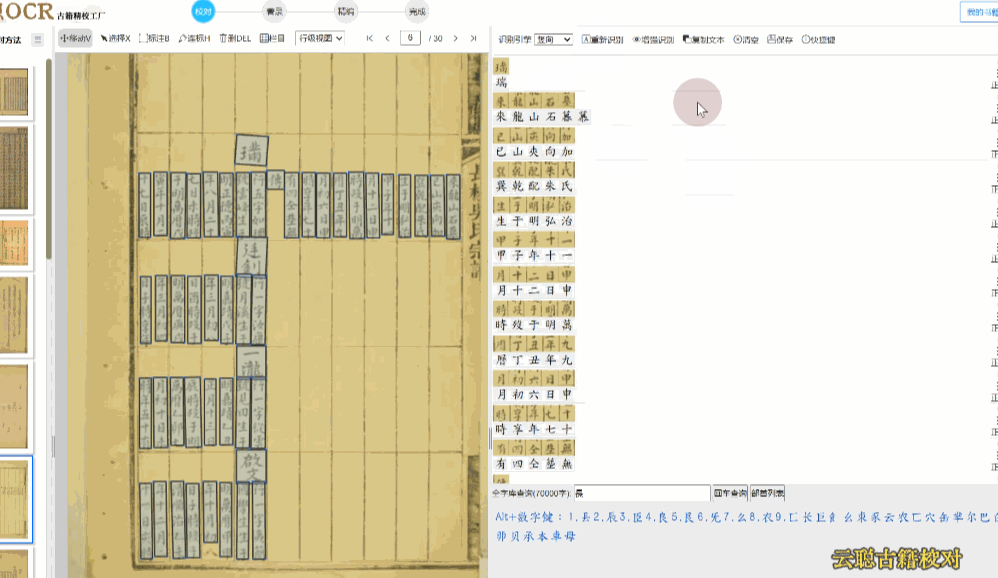
校对方法:系统已经有较好的支持,如果还是有错误,切换到栏目视图,画出栏目区块再进行识别
5、族谱版面
族谱、家谱类的古籍,手写体的抄本较多,多数页面按照家族辈分上下分层撰写,系统识别往往有语句的顺序错误。
校对方法:调整语序 或者 切换到栏目视图,画出栏目区块再进行识别
6、民国报刊版面
民国期刊栏目较多,默认识别的会出现语序杂乱的情况。
校对方法:切换到栏目视图,画出栏目区块再进行识别 或者 选择识别引擎为"混排",重新识别
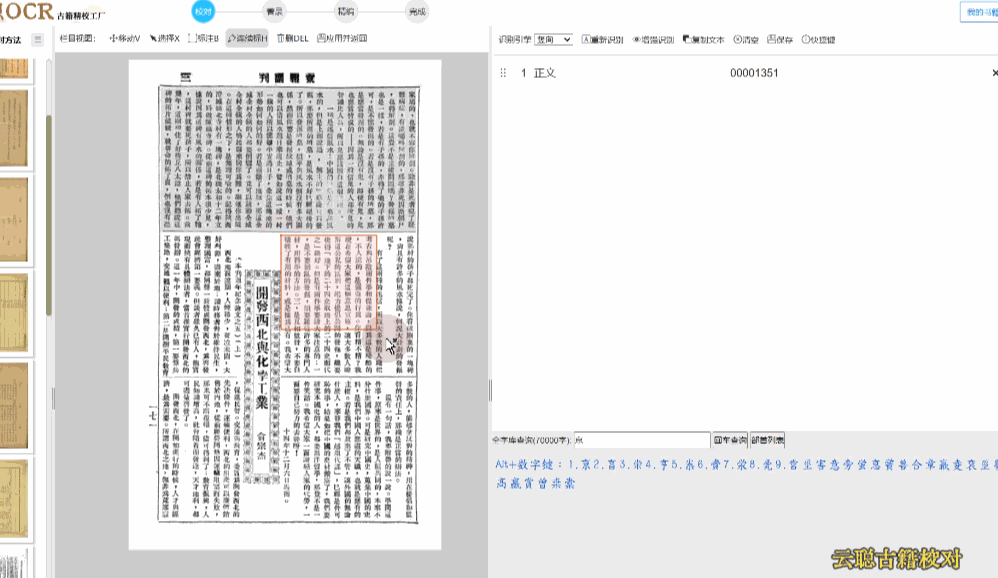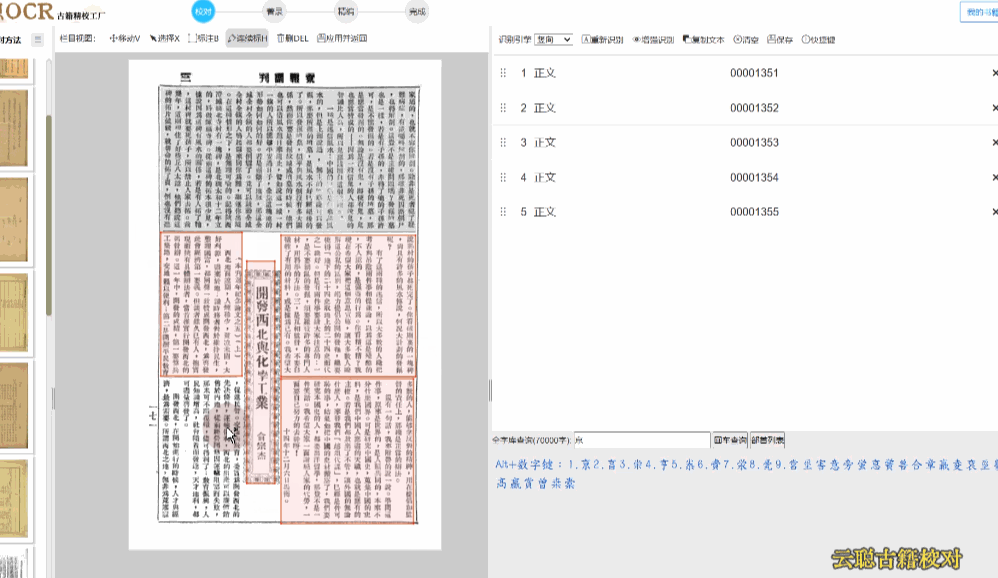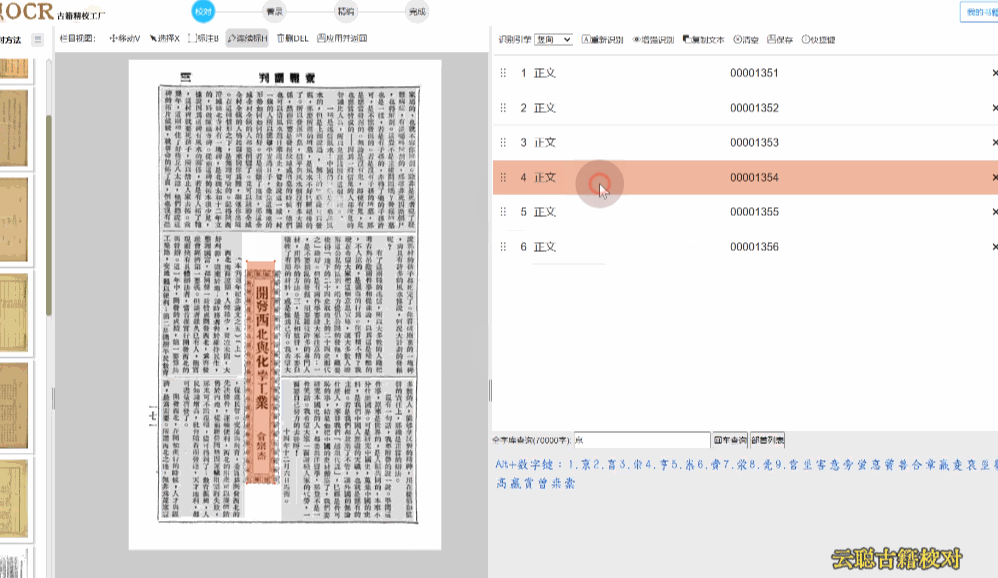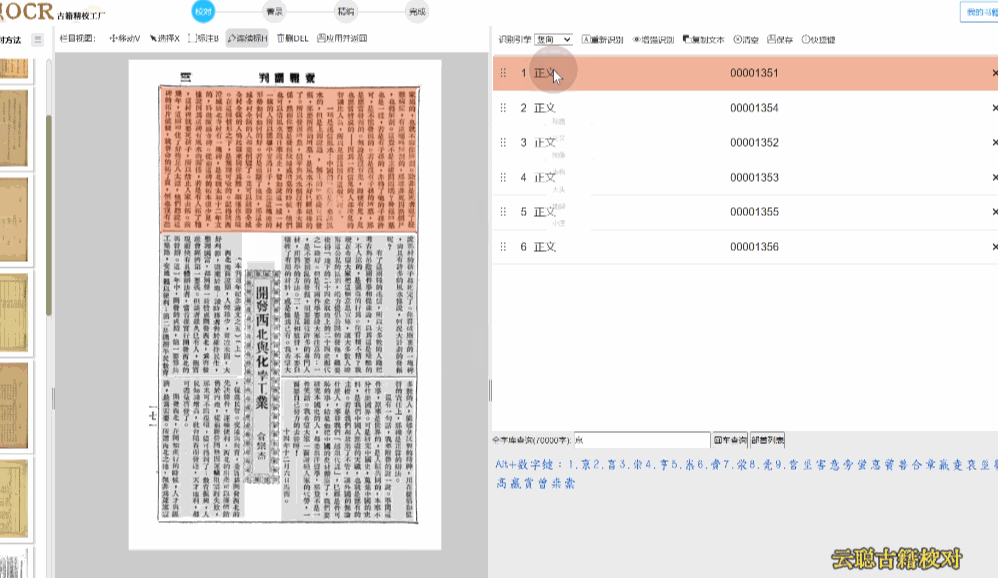
7、横向繁体版面
文本方向为横向,多出现于60年代的期刊报纸。
校对方法:横向繁体注意在识别的时候,选择识别引擎为"横向"即可

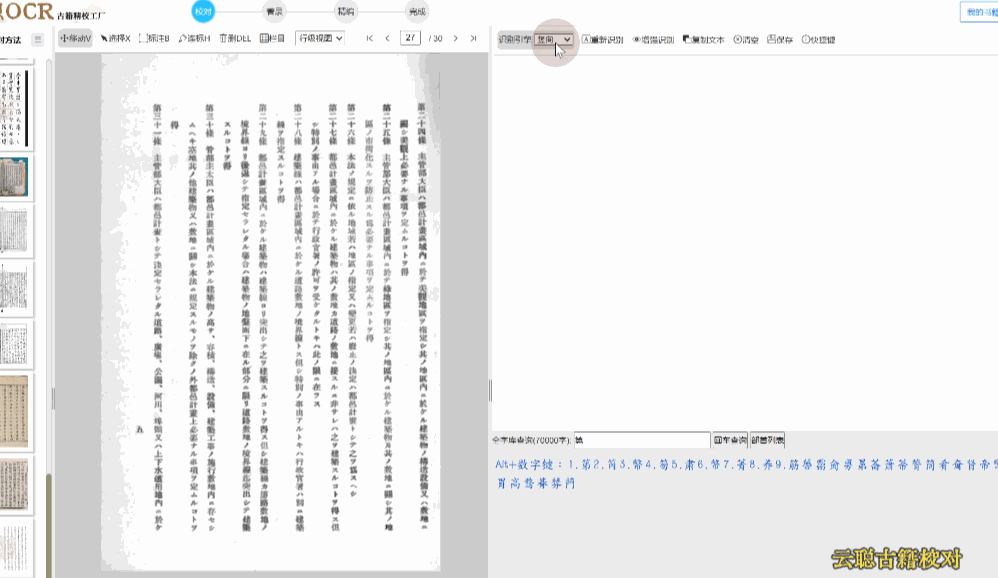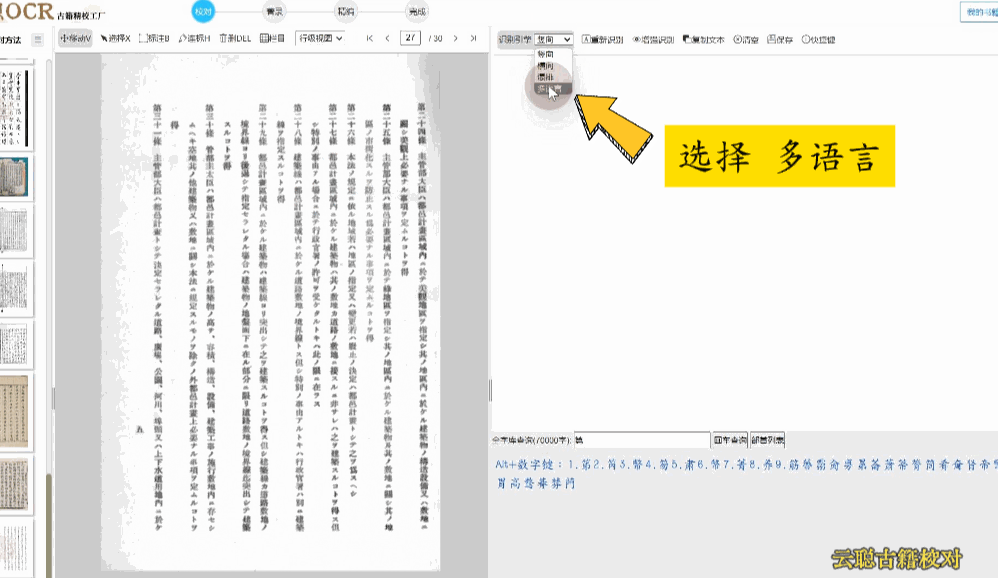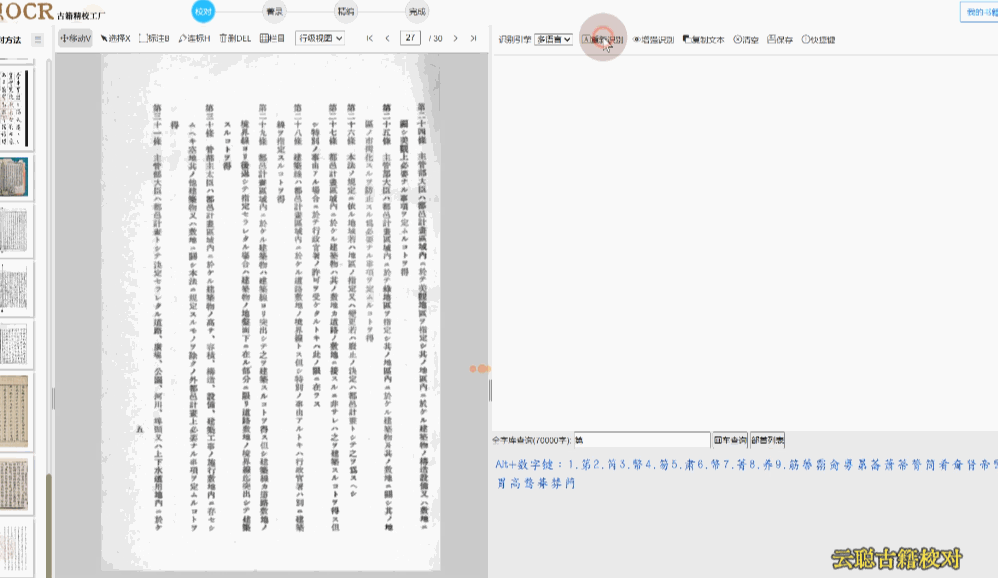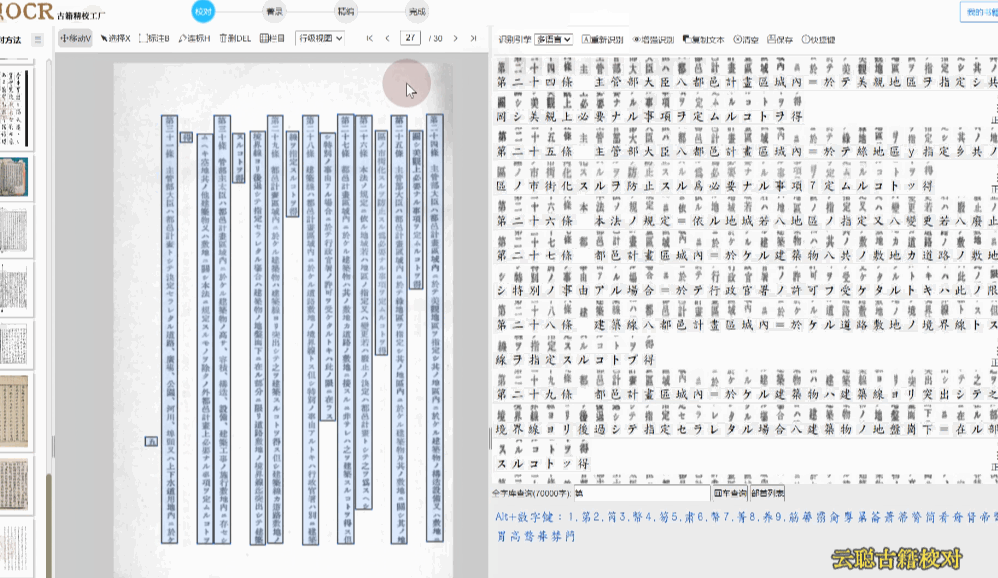
8、多语种版面
多语种版面就是文字中有日文、韩文、英文等字符。
校对方法:选择识别引擎为"多语言",重新识别